Coherentism and the case for complementary science
A review of Hasok Chang's "Inventing Temperature".
Most of us have used a thermometer at some point in our lives. If you’re like me, you didn’t question how this instrument works or ask how it is that we can be sure of its readings. With some exceptions—thermometers can, after all, break—we assume the thermometer is valid.
Yet as Hasok Chang’s Inventing Temperature makes clear, our collective confidence in a thermometer’s readings was hard-won. The history of thermometry (i.e., the science of measuring temperature) involves centuries of incremental developments, setbacks, theoretical disagreements, and crucially, meticulous empirical measurement. As Chang argues, mapping this history can grant insight not only into how and why we can trust our thermometers, but into scientific epistemology more generally.
In the book, Chang covers several concrete problems faced by scientists trying to refine and validate instruments for measuring temperature. Most fundamentally: how do we validate a new instrument or construct when we have no “ground truth” against which to compare it? Even if we make use of some “fixed point”—like the boiling point of water—how can we be confident that the fixed point is actually fixed? And having anchored our scale to these fixed points, how do we tell the exact temperature between those values? Or, even more challenging, how do we extrapolate beyond the scale to measure temperatures that are very hot or very cold?
These challenges were not solved immediately. But scientists did, over time, construct increasingly refined methods for measuring temperature and, importantly, for being confident in these measurements. This process of gradual refinement—which Chang called epistemic iteration—involved considerable trial-and-error: no single step was absolutely “correct” or even fully justifiable, but over time, the accumulation of empirical measurements and theoretical constructs allowed for the creation of a coherent, mutually supporting, web of beliefs and epistemic practices.
So how did they do it, and why is it worth learning about?

Chang begins and ends the book with a case for complementary science.
Complementary science stands, as the name implies, in a complementary relation to specialist science (what we might typically just call “science”). At this point, contributing to specialist science is very difficult; with considerable training and expertise, one might hope to contribute to a particular field, but the barrier to entry is still quite high. Chang makes clear that this is not a bad thing—specialist science is probably our best method for constructing empirically-grounded knowledge claims about the world.
Yet Chang argues that the non-specialist can still play an important role in the scientific enterprise through complementary science:
Complementary science asks scientific questions that are excluded from current specialist science. It begins by re-examining the obvious, by asking why we accept the basic truths of science that have become educated common sense. Because many things are protected from questioning and criticism in specialist science, its demonstrated effectiveness is also unavoidably accompanied by a degree of dogmatism and a narrowness of focus that can actually result in a loss of knowledge. (pg. 3)
In other words, complementary science does not take scientific knowledge for granted. It asks what combination of empirical measurements, technical achievements, epistemic practices, and institutional structures allowed us to acquire that knowledge. This involves a fair bit of history, but it can also produce philosophical insights: studying the historical processes behind knowledge creation can inform epistemological theory.
Chang further suggests that complementary science can serve an important role in scientific education. Take the claim that the Earth revolves around the sun. If you can’t explain how you know this, is it really appropriate to assert that you know it at all? Chang argues that the answer is “no”: such a belief cannot be properly called scientific knowledge per se. Of course, it would be impractical for each individual to learn the history of every scientific knowledge claim. But Chang suggests that we could do much more to encourage a truly participatory scientific education—and that part of being an informed citizen in the modern world consists not only in reciting a litany of claims but in explaining the justification behind those claims.
Another value of complementary science is contextualization and rediscovery. It is far too easy, now, to look back at overturned theories—geocentrism, phlogiston, and more—and think of their proponents as hopelessly misguided. But people often believed in particular theories for good reasons, and in fact, the reasons those theories were overturned were not always as principled at the time as we might now imagine. At minimum, this teaches humility and provides a broader context for what we think of as “modern science”; more ambitiously, it might lead us to explore promising roads that were abandoned for various social or institutional reasons.
Finally, the study of other disciplines like thermometry can, if we’re lucky, inform modern debates and challenges. As I’ll discuss towards the end of this essay, perhaps the major contemporary measurement challenge is benchmarking the capabilities and behaviors of large language models (LLMs) and other Artificial Intelligence (AI) systems. There are, of course, many points of divergence between thermometry and the scientific study of LLMs; but as I’ll suggest, even these differences can be instructive about the kind of challenge we now face.
Let’s start, then, with the idea of epistemic iteration.
Suppose one observes that liquids tend to expand when heated and contract when cooled. Already this represents the seed of insight: some externally observable process (the expansion or contraction of liquid) can be mapped onto sensory experience (the sensation of hot or cold). One could take advantage of this insight by devising a simple instrument that measures ordinal (as opposed to numerical) changes in temperature, as indexed by the movement of liquid up or down a narrow tube; such an instrument is called a “thermoscope”.
Epistemically, however, the relationship between sensory experience and the readings on a thermoscope is complex. In some cases, we might allow for the thermoscope’s reading to “correct” our sensory experience: for instance, a lukewarm bowl of water might feel hot or cold to the touch depending on whether we’ve just placed our hand in something cold or hot—whereas a thermoscope would, naturally, produce the same reading in each situation.
Yet recall that the original insight for the thermoscope came from mapping some externally observable process onto sensation. In that sense, we might say the thermoscope’s readings are validated or “justified” by sensation. This puts us in a strange situation: if the thermoscope is only valid with respect to sensation, how can it also “correct” sensation? Moreover, how do we know we can trust our senses? Chang writes:
From ancient times, philosophers have been well aware that there is no absolute reason for which we should trust our senses. That brings us to the familiar end of foundationalist justification, unsatisfying but inevitable in the context of empirical science…The groundlessness cannot be contained: if we follow through the empirical justifications we give for our beliefs, we have done in the case of thermometric fixed points, we arrive at bodily sensation; if that final basis of justification is seen as untrustworthy, then none of our empirical justifications can be trusted. If we accept that sensations themselves have no firm justification, then we have to reconceptualize the very notion of empirical justification. (pg. 42)
The problem, in Chang’s view, is that the traditional way of conceiving of “justification” in philosophy of science is rooted in the idea of a logical proof, in which a proposition is deduced from other propositions. In this case, however, we see that such a demand creates a kind of infinite regress: how deep do we have to dig to find the foundation?
Chang suggests, first, that justification follows something more like an iterative process:
Although basic measuring instruments are initially justified through their conformity to sensation, we also allow instruments to augment and even correct sensation. In other words, our use of instruments is made with a respect for sensation as a prior standard, but that does not mean that the verdict of sensation has unconditional authority. (pg. 43)
Why, then, give sensation any authority at all? Here, Chang invokes a kind of pragmatism: sensation is accepted as a “prior” standard merely because it is, literally, prior to other standards—and we just don’t have an alternative. As described above, the relationship between these “prior” standards and a later standard (which is based, in turn, on those prior standards) is not one of strict logical deduction, nor is it even one of strict consistency, given that the later standard can contradict (and correct) the prior standard.
Chang argues that justification should be conceived not in terms of logical deduction from some set of foundational axioms (a viewpoint called foundationalism), but rather as a self-correcting, iterative process. This process leads, ideally, to a “spiral of self-improvement”: a prior standard can motivate empirical investigations that ultimately lead in the creation of new standards improving upon the original, prior standard.
Chang refers to this process as epistemic iteration:
Epistemic iteration is a process in which successive stages of knowledge, each building on the preceding one, are created in order to enhance the achievement of certain epistemic goals….in each step, the later stage is based on the earlier stage, but cannot be deduced from it in any straightforward sense. Each link is based on the principle of respect and the imperative of progress, and the whole chain exhibits innovative progress within a continuous tradition. (pg. 45-46)
We can use this framework to conceptualize the history of thermometry. In the earliest stages, we presumably relied on bodily sensation to assess the temperature of something. As we’ve seen, this motivated the second stage, which involved the invention of instruments like thermoscopes: measuring devices that exploited a physical property of fluids (i.e., that they expand when heated) to provide a somewhat more reliable index of temperature—yet one that was originally grounded in the earlier, noisier index.
These thermoscopes, as I wrote above, were ordinal. The relative height of liquid in a narrow tube indicates whether some substance is hotter than another. It doesn’t tell us, however, exactly how much hotter. That requires a numerical scale, which in turn relies on the identification of “fixed points” (i.e., for anchoring the scale) and a method for “graduating” the scale (i.e., for interpolating between those points). These challenges are the primary subjects of chapters 1 and 2, respectively.
Each of the primary chapters in Inventing Temperature is divided into two sections. The first section covers some historical challenge in considerable detail, naming the main “players” and describing the steps they undertook to address that challenge; the second section uses this as the basis for drawing more abstract, generalizable lessons about how science is conducted. We might think of these chapters as making the case, implicitly, for what Chang calls “complementary science”: as I mentioned above, he makes the case explicitly at other points in the book, but these chapters serve as a kind of proof-of-concept that the approach is viable and even useful.
Some readers will likely be drawn more towards the philosophical distillations and might even be tempted to read only the fifth chapter of the book, which explicitly makes the philosophical case for coherentism and epistemic iteration. In my view, however, those distillations are most legible given the historical context. I’ve done my best, above, to provide something like an abstraction of what Chang calls epistemic iteration—but I believe that the impression it leaves will be somehow sparser and of less depth than the one acquired by actually reading about the history.
Perhaps most importantly, the history provides the reader with a deep sense of how challenging some of these questions really were, and how much careful empirical work was required to address them. I consider one of these examples in the section below.
Suppose we’ve constructed a thermoscope and anchored its readings to some fixed points we take to be relatively reliable (e.g., steam temperature). This process is itself not without some complexity, given the difficulty in identifying a stable fixed point (the boiling point of water, it turns out, is subject to fluctuation given atmospheric pressure, the material of the vessel, the water’s purity, and other factors). But assuming we’ve overcome those difficulties, we still face the question of how to interpolate between them and, crucially, how to ensure that different instruments provide the same reading for the same substance.
The naive solution would be to divide our thermoscope into equal intervals between those fixed points:
For instance, the centigrade scale takes the freezing and boiling points of water as the fixed points. We mark the height of the thermometric fluid at freezing 0º, and the height at boiling 100º; then we divide up the interval equally, so it reads 50º halfway up and so on. The procedure operates on the assumption that the fluid expands uniformly (or, linearly) with temperature, so that equal increments of temperature result in equal increments of volume.
The solution is naive, though, because the assumption is unwarranted: is it really the case that fluid expands linearly with temperature? It seems conceivable that a fluid might expand logarithmically, quadratically, exponentially, or in some other fashion. How could we possibly figure this out? Chang calls this the problem of nomic measurement, which he defines as follows:
- We want to measure quantity X.
- Quantity X is not directly observable, so we infer it from another quantity Y, which is directly observable.
- For this inference we need a law that expresses X as a function of Y, as follows: X = f(Y).
- The form of this function f cannot be discovered or tested empirically, because that would involve knowing the values of both Y and X, and X is the unknown variable that we are trying to measure. (pg. 59)
Moreover, different fluids might expand in different ways. There were several contenders in late 1700s and early 1800s—atmospheric air, mercury, and ethyl alcohol—which themselves represented a reduction from the original variety of substances that had been proposed (including oil, salt water, and petroleum). Which provided the most reliable measure of temperature?
One modest improvement over the naive assumption of linearity comes from the scientist Jean-André De Luc, who also played a significant role in establishing the instability of the boiling point of water. To address the question of which substance provided the best thermometric substrate, De Luc employed an approach called the “method of mixtures”:
Mix equal amounts of freezing water (at 0º centigrade, by definition) and boiling water (at 100º, again by definition) in an insulated vessel; if a thermometer inserted in that mixture reads 50º, it indicates the real temperature. Such mixtures could be made in various proportions (1 part boiling water and 9 parts freezing water should give 10º centrigrade, and so on), in order to test thermometers for correctness everywhere on the scale between the two fixed points.
If we assume the temperature of the resulting mixture can be derived from the relative proportion of boiling and freezing water, we can use that as a kind of “ground truth” against which the readings of any given thermometer can be compared. Using this technique, De Luc compared the expansionary properties of several substances, including mercury, ethyl alcohol, and olive oil. His results pointed to the superiority of the mercury thermometer, as reflected in smaller deviations from the assumed “ground truth” for a variety of different temperatures.
The problem, however, is that the method of mixtures makes some assumptions of its own: namely, it assumes that the “amount of heat needed in heating a given amount of water was simply proportional to the amount of change in its temperature” (pg. 64). That is, the amount of heat required to raise the temperature of a given amount of water should not depend on the temperature of the water. This assumption was challenged by the growing popularity of the caloric theory, the idea that heat consists of (or is caused by) a self-repulsive fluid called caloric, which flows from hotter bodies to colder bodies. Caloric theory itself had multiple strands, but each of these strands found reasons to object to De Luc’s crucial assumption.
While caloric theory didn’t necessarily offer a better way of calibrating fluid thermometers, it did imply that the behavior of heat (caloric) was purest in gases:
In gases the tiny material particles would be separated too far from each other to exert any nonnegligible forces on each other; therefore, all significant action in gases would be due to the caloric that fills the space between the material particles. (pg. 69)
This suggested to many proponents of caloric theory that gas thermometers would be inherently superior to liquid thermometers. This was followed by a flurry of theoretical developments made by investigators like Pierre-Simon Laplace in an effort to more precisely define the concept of temperature. These developments, unfortunately, involved a number of additional assumptions (e.g., that gases are in thermal equilibrium and uniform in density), none of which were adequately defended or even (according to Chang) empirically testable.
Thermometry, at this point, took a decidedly anti-theoretical turn. In Chang’s words:
The principles of thermometry thus endured “the rise and fall of Laplacian physics” and returned to almost exactly where they began. The two decades following Laplace’s work discussed earlier seem to be mostly characterized by a continuing erosion in the confidence in all theories of heat. The consequence was widespread skepticism and agnosticism about all doctrines going beyond straightforward observations. (pg. 74)
It is in this historical context that Henri Victor Regnault—the hero of the chapter—enters the story. Regnault was skeptical of grandiose theories and of any measurement technique relying on strong assumptions. He endeavored, therefore, to construct and validate thermometers using approaches that made as few assumptions as possible (and ideally none).
How exactly did Regnault achieve this? Part of the answer was aiming for something slightly less ambitious in its claims—though not in its empirical scope. Regnault’s goal was establishing comparability between thermometers:
If a thermometer is to give us the true temperatures, it must at least always give us the same reading under the same circumstance; similarly, if a type of thermometer is to be an accurate instrument, all thermometers of that type must at least agree with each other in their readings…Comparability was a very minimalist kind of criterion, exactly suited to his mistrustful metrology. All that he assumed was that a real physical quantity should have one unique value in a given situation; an instrument that gave varying values for one situation could not be trusted, since at least some of its indications had to be incorrect. (pg. 77)
Readers familiar with psychometrics might recognize the seeds of concepts crucial to construct validation in modern empirical science, such as test-retest reliability and convergent validity. The former principle states that the same instrument applied under the same conditions of measurement should yield (roughly) the same results; the latter states that different measures of the “same thing” (e.g., working memory) should again yield (roughly) correlated results.
While comparability was not a new concept, Regnault approached the problem with a particular degree of care and meticulousness that allowed him to establish the comparability (or lack thereof) of different thermometers on much firmer empirical grounds. In a comparison between mercury and air thermometers, he found that mercury thermometers—as the caloric theorists had feared—did indeed yield more variable measurements, i.e., they were less comparable, particularly at temperatures above 100˚ centigrade.
In the analysis section, Chang connects this achievement back to the problem of nomic measurement: part of Regnault’s success came from recognizing that a solution to this problem could not come purely from so-called “stage 2” thermometric standards (i.e., thermoscopes). Rather, each proposed “stage 3” standard (e.g., mercury or air thermometers) had to be judged by their own merits—and in Regnault’s view, comparability was both important and tractable as an epistemic virtue.
Chang writes:
The requirement of comparability only amounts to a demand for self-consistency. It is not a matter of logical consistency, but what we might call physical consistency. This demand is based on what I have elsewhere called the principle of single value…a real physical property can have no more than one definite value in a given situation. (pg. 90)
As Chang notes, this is an assumption: thus, it is not the case that Regnault made zero assumptions in his work. Moreover, the principle of single value is not merely a matter of logical consistency or non-contradiction (as would, say, the principle that a temperature can be both 15˚C and not 15˚C). Indeed, there are plenty of non-physical properties that we allow to take on multiple values, such as an object possessing multiple names or a mathematical function with multiple outputs. But because of the physical nature of temperature, we have a commitment (whether implicit or explicit) to the principle of single value. And crucially, this minimal commitment is what allowed Regnault to ground his (very extensive!) empirical investigation.
There is much more that I cannot hope to cover here, both on the topic of Regnault’s work specifically and on the history of thermometry more generally. This history includes a number of remarkable detours and digressions—each stemming from a seemingly intractable problem—such as the Wedgwood scale, a temperature scale developed by the potter Josiah Wedgwood to measure the temperature of extremely hot objects, i.e., at temperatures that would simply melt a mercury thermometer. The scale was based on the observation that clay shrinks when heated above so-called “red heat”, and the degree of shrinkage associated with a particular cube of clay could be used to approximate the heat of a room; the scale was ingenious, particularly Wedgwood’s technique for calibrating it with existing mercury thermometers, though it eventually became obsolete.
Rather than discuss these detours in detail here, I’d like to close this essay by turning briefly instead to another, more modern, measurement challenge: the problem of “benchmarking” the capabilities and safety of large language models (LLMs).
Because LLMs aren’t (for the most part) explicitly designed to solve the specific tasks for which people would like to deploy them—indeed, much of the promise of Artificial General Intelligence (AGI) is that a “general-purpose” system can solve a range of tasks and challenges—it’s not always clear from the design properties of a model what it will be able to do. That’s why measuring these behaviors is generally seen as very important: ostensibly, we might want to know what an LLM can or can’t do before we deploy it to do something; we might also want to know that it is safe to deploy according to a number of criteria we consider crucial. In some cases, regulatory legislation is even crafted under the assumption that decisions about how to monitor and deploy LLMs can be directly related to measurable benchmarks (e.g., “safety audits”). It also matters for a basic science of LLMs, i.e., the emerging field of “machine cognition”: in the view of many (including myself), a scientific account of LLMs ought to be able to explain what these systems can do, why, and relate these emergent behaviors to their constitutive design properties.
The capabilities and behaviors in question are, notably, quite a bit fuzzier than something like temperature. We speak of constructs like “reasoning”, “planning”, “Theory of Mind”, “deception”, “alignment faking”, “scheming”, and even “consciousness”. To the extent that these constructs are measurable at all, measuring them is a markedly different task from that of measuring temperature.
For one, temperature is intimately connected to sensation: regardless of whether one is a realist about the existence of a quantity called temperature, the fact remains that what we call temperature is perceived by our senses. Moreover, variance in this quantity systematically covaries with other observables, like the expansion or contraction of a liquid—which is precisely what allows us to build instruments like thermoscopes or, eventually, thermometers. And as Chang notes, we’ve been able to develop remarkable theoretical scaffolding that supports and explains these facts by relating them to physical laws.
Now, as I’ve argued throughout, the victories of thermometry were still hard-won. But they were won against a backdrop that made them viable at all: we exist in a universe where we can anchor our measures of temperature against “fixed points”, and where problems of nomic measurement can be (painstakingly) overcome with meticulous empirical observations and comparison. There’s a degree of serendipity to our success—yes, the boiling point of water is less stable than commonly thought; but under the general conditions under which the boiling point of water was used as a fixed point, it was relatively stable; the same is true for steam. It didn’t have to be this way!
At first glance, this does not give me considerable confidence in our ability to “benchmark” the capabilities of LLMs. For example: what is the equivalent of a “fixed point” in assessing something like reasoning? How do we know, having developed a benchmark, that equal intervals in benchmark performance correspond to equal intervals in the underlying capability? How could we hope to extrapolate beyond the putative endpoints of a scale?
An objection here might be that I’m asking too much: after all, part of the point of Inventing Temperature is that thermometry proceeded in fits and starts—it is only through the lens of history that we can impose something like structure and call the process by which that structure was achieved “epistemic iteration”. But epistemic iteration, as Chang notes, depends on some indicator of progress. These indicators need not be derived from foundational axioms; but even under a coherentist paradigm, we need some way to determine and compare the validity of various instruments.
This is not to say progress cannot be made. A natural fixed point, for instance, might be something like “human performance” on some task. It’s worth noting that this is not exactly analogous to the boiling or freezing point of water. For one, there is much less stability across humans on a given task than in the boiling point of water; but perhaps this objection can be defused by suggesting that we compare to the top X% of humans on a given task. More importantly, however, the mean (or maximum) performance of humans on a task does not tell us whether the task measures the thing we want to measure: it situates humans on some scale (of indeterminate intervals) relative to the LLMs in question. Validity, then, is not achieved merely through the use of a human comparison.
Perhaps the closest example of something like fixed points in LLM benchmarking comes from the much-discussed METR graph (below). Here, LLMs are measured in terms of their success rate performing tasks that take various amounts of time for humans to perform (e.g., from 4 seconds to 10 hours). This represents a conceptual advance in two ways: first, the tasks themselves are selected in terms of putatively useful capabilities (like “counting words in a passage” or “training a classifier”); and second, performance is grounded not only in a numerical score (e.g., “accuracy”) but aggregated in terms of time, which gives us a kind of common “currency” with which to compare models and tasks.
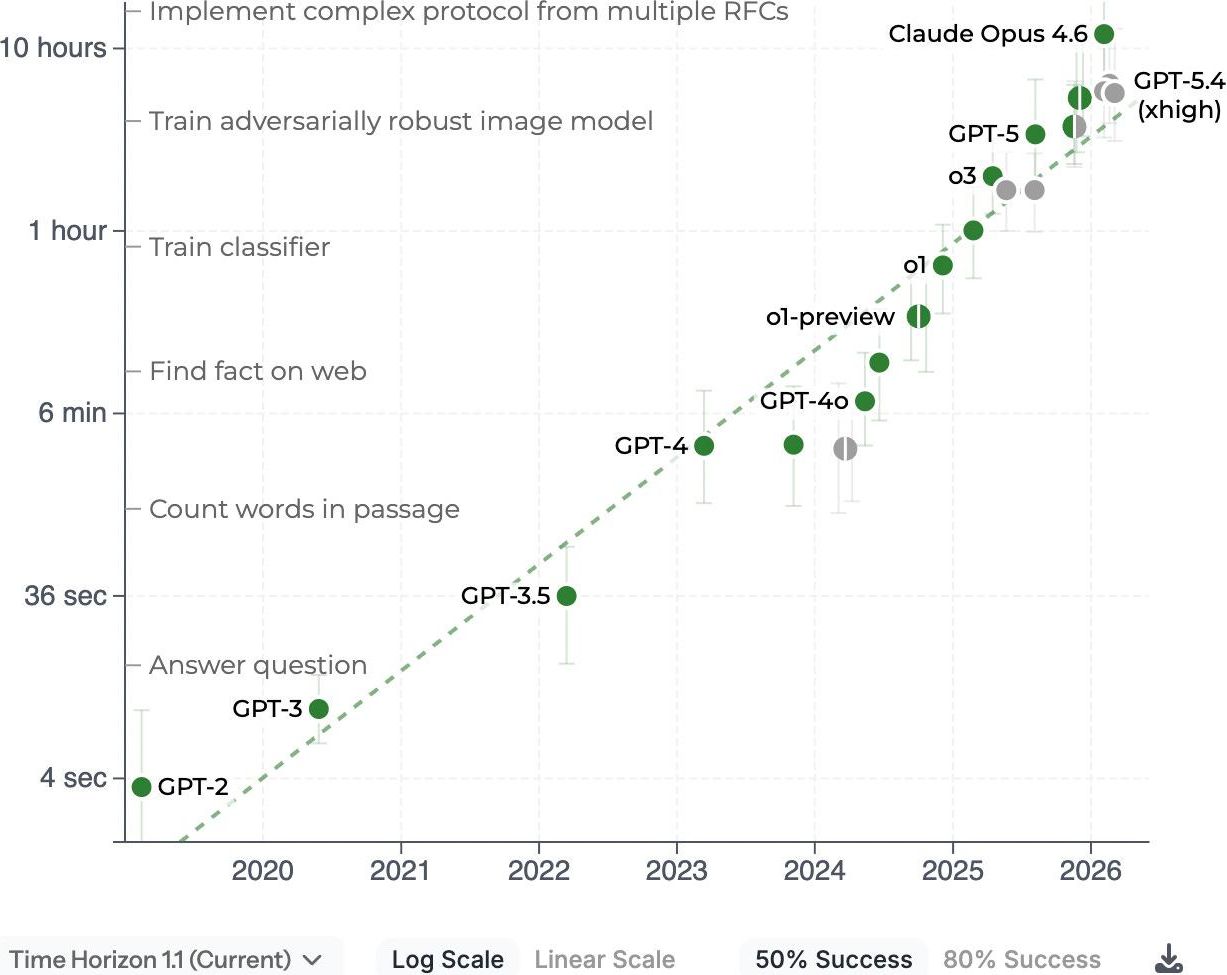
Screenshot of the much-discussed METR graph, which measures the ability of LLMs to perform tasks that take humans various amounts of time to perform.
This is not to say the approach is perfect!
As others have pointed out, some important tasks of interest may not be so easily defined and modularized relative to other tasks. We might think of this as analogous to the problem of the “central processor” that the philosopher Jerry Fodor raises in The Modularity of Mind: many mental processes of interest might be deeply intertwined with many other mental processes, making it virtually impossible to study and isolate them using the traditional tools of experimental psychology; better, then, to focus on those putatively “modular” processes, a category in which Fodor places (among other things) vision, audition, and aspects of language processing. Similarly, it might be objected that many human activities—economic or otherwise—cannot be easily “decomposed” into easily measurable constituents.
Perhaps a more fundamental problem is, yet again, generalizability: how representative, really, are the various 10-hour tasks that METR has included in its sample? The problem here is twofold. Within a category, tasks might be quite heterogeneous, and they might become increasingly so as the time horizon increases; we might expect, then, to observe wider and wider error bars. Heterogeneity is also, crucially, a problem for extrapolation: to what extent does a model’s ability to solve one set of 10-hour tasks predict its ability to solve another? A reader might object: is this not an empirical question? And it is, to some extent: certainly, we can measure the performance of models on various tasks that take humans 10 hours to complete and compare them across the entire set for which we have empirical observations. But it is also obvious that we cannot hope to empirically exhaust the space of possible tasks; sampling from this theoretical population is required, which therefore demands some degree of extrapolation to tasks for which we don’t have direct observations.
How do we know whether the performance of one task is indicative of performance on another without measuring performance on both tasks? This is roughly analogous to what some philosophers call the “extrapolator’s circle” in the study of model organisms: if justifying extrapolation is an “empirical question” that requires corroborating in the target (e.g., a human) findings from the model (e.g., a rat), what is the point of the model? Either we can measure the target directly (in which case the model is unnecessary) or we can’t (in which case some extrapolation, and thus some uncertainty is inevitable).
Clearly, scientists muddle through: after all, we have thermometers; and biologists rely on (evolving) norms about when and how to extrapolate from model organisms to humans on the basis of various heuristics, including shared evolutionary history and conserved causal mechanisms. Part of me is tempted to suggest, here, that these problems are not typically solved by philosophers—that the discipline of history and philosophy of science (HPS) is better suited to a kind of retrospective accounting, rather than prospective planning. Perhaps, like thermometry, the challenges of benchmarking LLM capabilities will be solved through a cumulative, error-prone process we will one day give the label “epistemic iteration”.
Maybe so. But I also think it is wise to remember that we are not entitled to success here: the universe need not reorganize itself to the constructs we impose, and the markers of progress necessary for epistemic iteration may simply not materialize. And perhaps progress, when it occurs, is only achievable when some amount of philosophical hand-wringing is applied.
In either case, I can’t say I’m confident. If there’s anything I’ve learned from the history of thermometry, it’s that hard-won victories are rarely won in the absence of some mysterious property we might call serendipity.
Your message is stored now and emailed to the author after the contest ends. The author can reply to you, but their identity stays hidden unless they choose to respond.