State of competitive debating (unions) address
Li Shengwu is atypical many times over. He is a renowned economist. He is a grandson of Singapore’s founding father who emigrated to the United States. He received tenure from Harvard University at the age of 39. In another lifetime--that of the Obama era--he was also extremely successful in the world of competitive debate.
When I use the phrase “competitive debate,” I don’t mean the activity that free speech advocates tell you is plagued by woke critical theorists and evidence packets. That’s American high school debate. There is a worldwide network of universities--a set of regional “circuits”-- that facilitates something closer to actual debate. The main format in which it hosts tournaments is called British Parliamentary. (See the second tab for an explainer, but basically, four teams of two give 7-minute speeches on a topic they had 15 minutes to think about with no internet access.) At the higher levels, speeches in BP debates are often quite persuasive to normal people: there are no lists of studies read out at 350 wpm, no judges who “adjudicate from a Marxist paradigm,” and no monologues about nuclear war in debates about normal things like legalizing drugs.
A number of US universities are quite committed to this circuit. In January 2025, Bates College made it to the grand final of the World Universities Debating Championship (WUDC), and Dartmouth College won it. Sadly, though, far more US universities remain committed to the stupid version of debate.
Li Shengwu’s accomplishments during his debate career--part of which he spent representing Stanford--and his outsize influence on the global debating circuit are thus quite interesting to examine in our time. He was the single best performer at the 2010 World Universities Debating Championship, but he’s best known (at least among young debaters) for a recording of a speech he gave in a round he lost. He was defending the belief that the media should show the full horrors of war. It was the fifth of the eight speeches in the 2010 final. With fifteen years of hindsight, it seems extremely obvious to open with Tacitus, but the first time a fifteen-year-old hears his delivery of “they make it a wasteland, and they call it peace,” it strikes her with force. This is similar to the experience of reading his blog Trolley Problem in 2025.
Trolley Problem hosts 17 posts (some essay-length, some tweet-length) uploaded over the course of 2012. Li’s first post, “a statement of purpose,” from January 22, proclaims: “This is not going to be your standard debating blog. There will be almost no news about ongoing tournaments, and no hand-wringing about which-teams-will-break-on-what-points-this-weekend.” Not only has this “standard” for debating blogs died out: most of those “standard” blogs are no longer available for the public to find and read. (The most plausible explanation is that this kind of gossip has moved to Discord servers and Facebook Messenger group chats and that no one bothers paying for their college-era blog domain anymore.)
Trolley Problem is an unusual window into Obama-era debating. This review will construct a window into Trump-era debating, and it will comment on how the landscape has changed. Post-mortems of the golden age of American universities and free speech are common these days. It seems relevant to review the evolution of American debating norms as they relate to the global circuit.
Selecting good, fair topics for debates
The restriction of the set of topics considered “debatable” is a perennial concern among campus speech watchers. Among university debaters, it is theoretically a concern, but it is secondary to the much more present concern of actively choosing a handful of good topics to debate each weekend from the ever-churning ocean of options. (While some American formats force students to argue the same topic many times per weekend many weekends per year, BP demands 4-8 distinct topics per tournament depending on how many rounds are taking place.)
Debaters are concerned with competitive integrity. The point of a debate competition is to sort a set of debaters according to how skilled they are at formulating and delivering arguments. It would be unfair to force some speakers to argue inherently unconvincing or inherently super-convincing positions. Keep in mind that British Parliamentary has four teams, two of which need to provide distinct new arguments for the same position--it would also be unfair to set motions (topics) that only have one or two main arguments on each side.
Apparently, the concern for “fairness” was prominent in 2012. In What does it mean to say “This motion is fair”?, Li says that “almost all debaters describe motions as “fair” or “unfair” in ordinary speech. In 2025, complaining that a debate was “so unfair” would come off as whiny. People are socially expected to at least be a bit more specific when critiquing motions: it’s a lot more common to say “I think this motion is shallow on opposition” when there are fewer arguments against a motion than for it.
Li argues that there exist increasingly statistically strict methods of determining a motion’s fairness. The strictest of the four definitions he settles on is that “a motion is fair if teams of equal skill level in every position have the same probability of coming first, second, third, or fourth.”
He immediately dismisses this as a poor definition because there are good reasons for there to be variance among a team’s expected performance in Opening Government (OG) at different skill levels.
Personally, I have much less sympathy for the rights of the least skilled competitors. Over a number of tournaments, each of them can expect to draw OG roughly an equal number of times. Penalizing teams for being bad is actually a good thing. To be fair, though, this may be a somewhat recent innovation: before the widespread adoption of specialized tournament formatting (tabulation) software, there was less capacity to ensure teams drew each position an equal number of times in addition to being power-paired (the standard format for determining matchups at tournaments).
Li then wonders if his second-strictest definition, “a motion is fair if teams of equal skill level in every position have the same expected number of team points,” is a reasonable one. It is certainly considered reasonable today. In the late 2010s, developers of the prominent tabulation software Tabbycat added a feature that allows tournaments to display the distribution of performances by certain positions for each motion.
Here are the statistics about the motions that were set at the 2025 World Universities Debating Championship. The most balanced motion was that of the sixth round:
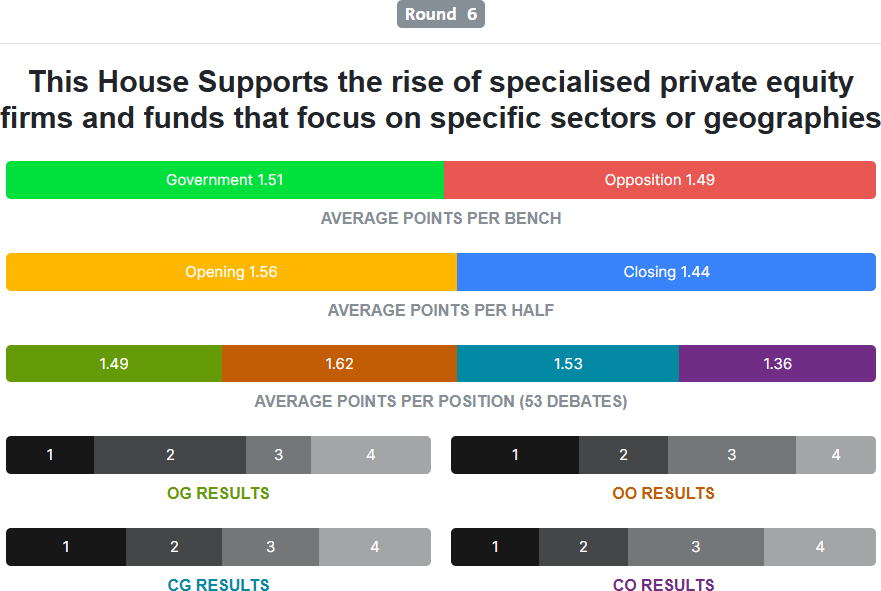
Perfect…
And the least balanced was that of the third round:
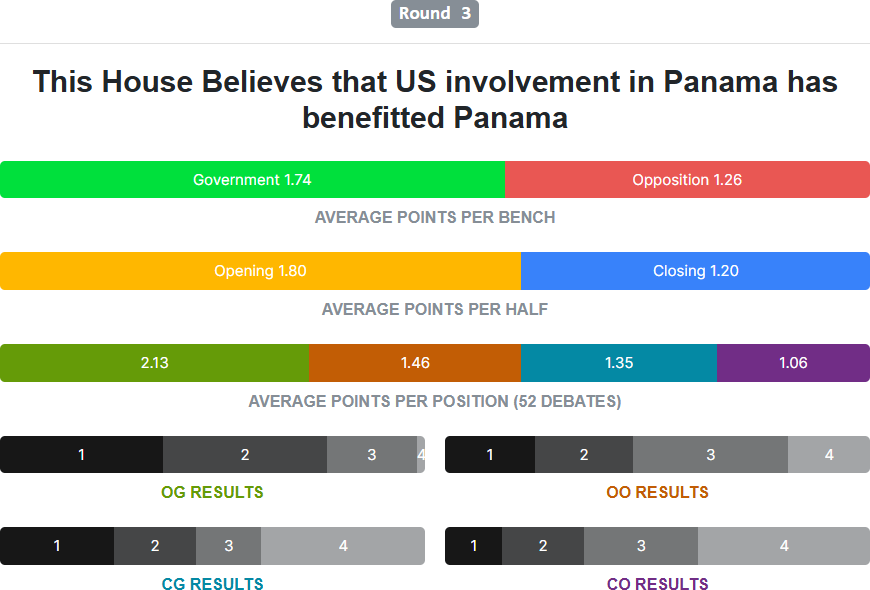
That canal was pretty beneficial.
I can explain why teams arguing in favour performed so much better than teams arguing against. The motion is worded poorly! Government teams don’t have to prove that US involvement in Panama has provided more benefit than harm. They just have to prove that Panama is better off than it would have been in the alternate universe without US involvement. American initiative with the canal and American investment with the banks are both obviously quite beneficial. Really, it’s a wonder that government teams didn’t overperform even more.
But this imbalance is nothing compared to the motions of the past. In Motion Fairness Analysis for Huber Debates 2012__, Li statistically tests the hypothesis that each motion from that tournament (which is hosted annually at the University of Vermont) is “fair.”
Some of them are about as close as you can get to balanced:

But some of them are decisively not:

This motion is clearly very flawed. The “public interest” is vague. This would create awful incentives for young men with main character syndrome. On the surface, it seems like there might be arguments in favour: this will incentivize whistleblowers to step forward! (Never mind that this was debated a year before the Snowden leaks.) But the arguments disperse when you look closely. There are usually legal ways to stand up against evil governments and corporations. When there aren’t, it’s still generally fine to impose penalties on lawbreaking: people who feel that speaking out is important enough will make the tradeoff.
Today, this level of imbalance is practically unthinkable in large debate competitions. Why? I can’t say for sure:
-
It seems that the teams that select motions--called the Chief Adjudicators (CAs)--take their roles much more seriously. In "Advice for new CAs setting motions," Li’s first suggestion is “don’t try to come up with motions on the day itself.” Even the most scattered CA teams will start assembling spreadsheets of motions a couple of weeks in advance.
- There is much more pressure on tournaments to recruit smart, accomplished people to CA teams.
-
As Li predicted, the ability to perform large-scale analysis of motions and tournaments makes it easier for CA teams to predict which kinds of motions will be balanced.
- It is also much easier to analyze the past performances of prospective CAs: people with track records of setting balanced motions are more likely to be hired.
Li understands that “fairness” is not the only consideration to be made when evaluating a motion. It is important to make university debaters argue about topics that are interesting and relevant. He praises motions about aliens and robots for the metaethical insights they produce; he encourages CAs not to let their personal obsessions leak into their motion-setting.
I’m sure you’re curious about whether university debaters restrict topics to a narrow patch of wokeness. They don’t really do that. Extreme tough-on-crime attitudes (round 8), opposition to affirmative action, and pro-religion pro-family arguments arise reasonably often. “This house would ban abortion” is a bit overdone for most modern tournaments, but a variant of it was set as recently as 2024 at the world’s premier round-robin tournament.
However, certain topics are overrepresented at tournaments. Can you guess which ones?
debatedata.io catalogues motions set at tournaments over the past few decades. Of the 32,342 motions it hosts at the time of writing, 1858 are tagged with “feminism,” 1374 are tagged with “minority communities,” and 790 are tagged with “LGBTQ+” (with about 100 motions of overlap between the three). That’s about 12% of all debates. 11,547 are tagged with “economics.”
“Economics” is a broader category. Everything from finance to trade to debates about the interests of individual workers gets the tag, as well as basically any motion that involves buying or selling anything (which includes a lot of Black Mirror-esque hypotheticals like “assuming feasibility, this house would allow individuals to sell units of their IQ). But overrepresentation doesn’t really follow woke patterns; it just correlates with the interests of the kind of university student who gets good enough at debate that people ask them to pick motions for tournaments.
How we ought to judge
University debates are judged by…panels of other university debaters. There are a few university students who exclusively compete or exclusively judge, but they are uncommon. (The reason for this is simple: judging provides unique insight into how to improve your own debating and vice versa.) But how should they decide which arguments are more persuasive? Vibes? Hours of poring over research papers?
In "What does a good judge believe?", Li answers the titular question:
Judges should have a defeasible presumption in favour of a moderate liberal position on most ethical issues. I use "liberal", not in the sense meaning "left-wing", but rather in the sense that would describe most intelligent university-educated people in the countries that we call "liberal democracies". By "defeasible", I mean that the presumption could in principle be overcome by a persuasive argument, and that the judge should listen to such arguments with an open mind.
What does such a moderate liberal judge believe? Here's a sketch: That judge has a strong belief in the importance of certain kinds of human goods - freedom, happiness, life, etc - though not a full theory about how trade-offs between these goods should be made, or a precise conception of what the good life is. That judge has a moderate presumption in favour of democracy, free speech, and equal treatment. That judge holds a defeasible belief in Mill's harm principle; that is, insofar as an action affects just the actor, the judge has a presumption against government action. That judge believes that important moral questions should be resolved by reasoned deliberation, not appeals to unquestionable divine authority. This is because a good judge is an open-minded individual of the sort likely to think that debating is a worthwhile activity.
I think this is very reasonable. Debating should ideally help students understand and grow more persuasive to normal people. This is a relatively normal set of principles to hold! More importantly, though, I’m happy to trade a bit of bias toward certain principles for a consistent increase in quality of debate. When there are zero grounding principles for judges, debates often devolve into assertion-offs where people with different values talk past each other.
The idea that judges should apply a uniform approach to assessing debates took hold in the community and eventually mutated into a 63-page manual. Li helped construct the “speaker scale” at the bottom of the document.
A tangent about scoring debates
Fierce discussions have been had about how to quantifiably score speeches. The scale theoretically standardizes scoring by asking the judge to consider:
-
How well-explained/logically sound the content was
- How vulnerable the content was to responses of varying ingenuity
-
How relevant the content was
-
How easy the speech was to follow
The issue, of course, is that these things are largely subjective. Analyzing the scores given by judges at the most recent WUDC shows that some judges consistently give teams scores that are far higher or far lower than their average performance.
But apparently speaker scores aren’t as subjective as one would think--or at minimum, their subjectivity does not render them useless. A recent paper showed that speaker points are empirically better than most other (feasible) metrics at predicting how teams will perform in elimination rounds.
What the American circuit is like these days
When I talk about the “American circuit,” I refer to the set of universities that participate in British Parliamentary debate. At this year’s United States Universities Debating Championship, this set included (in order of performance of their top team):
- Stanford University
- Columbia University
- Harvard University
- Princeton University
- UC Berkeley
- UC LA
- University of Rochester
- Bates College
- Williams College
- The Claremont Colleges
- University of Southern California
- University of Pennsylvania
- UW Madison
- Amherst College
- Drexel University
- Cornell University
- Brown University
- Colby College
- Bard College
- Middlebury College
- Hobart & William Smith Colleges
- Davidson College
- University of Vermont
- Morehouse College
Additional universities that participated in this year’s North American Universities Debating Championship:
- University of Chicago
- Northwestern University
- Yale University
- John Hopkins University
- Dartmouth College
- Swarthmore College
30 universities is not a small force, but it is far smaller than the group of universities in the American Parliamentary Debate Association who debate in the eponymous “fact”-slinging woke format. Some extremely successful international debaters also participate in APDA (on a spectrum from “once a year” to “frequently”). High performers in international debate seem to do well when they wade into APDA; the reverse is less often true.
Top American debaters have a strong grasp of the art of explaining technical things. The debaters who win international tournaments for American schools tend to create and leverage ridiculously effective catalogues of knowledge and argumentation. Writing out a ton of facts and arguments before tournaments (referred to as “matter filing”) has been common in BP debate for a long time, but today’s top Americans take that process to another level.
WUDC 2024 semifinalist Ryan Lafferty produced 520 pages of notes (about 100 pages of arguments and 400 pages of knowledge) in the lead-up to WUDC 2024. How do I know this? Because after the tournament, he released it online. One would think this would reduce his comparative advantage over other debaters: nope! He went on to win WUDC 2025. Then he published another 647 pages, at least 600 of which are distinct from his previous matter file.
How Americans compare to the rest of the world
Globally, the perception that American debaters and judges are bad has persisted for quite a while. Tenets of this argument include:
- Most Americans perform poorly at international tournaments
- For years, the vast majority of the US’s top performers at WUDC have been international students; the US can’t grow its own winners
- The homegrown Americans who are exceptionally good are ruining the activity by spitting out analysis at 200 wpm and beating inspiring speakers on “erm actually” esque technicalities
These things are true, but I (an outsider) no longer think they support the claim that the US is “worse at debate” than most other circuits.
It is certainly true that Australia is stronger. Out of the 48 teams that advanced to open elimination rounds at WUDC 2025, 18 were American, and 10 were Australian. Producing ~56% as many good teams with 8% of the population isn’t bad! The year before, it was even worse, with the US advancing 14 teams and Australia advancing 11.
Australia has a strong culture of holding “minis” that concentrate a bunch of extremely talented debaters into one place. It also seems more common to take courses from several universities, which allows people to practice with (and learn from) a wider set of speakers. But the Sydney Union’s half-a-million dollar yearly budget probably doesn’t hurt their ability to be competitive.
You could also argue that the UK is stronger. They also break more teams (proportionally to their population) than the US. But they are even more reliant on international students than the US is.
It is also true that many other countries’ relative strength is growing. The pandemic shifted debate tournaments to Discord and Zoom, which provided unprecedented access to the activity for people from around the world. After a long history of anglophone dominance, WUDC was won by two ESL teams in a row--Zagreb in 2021 and BRAC University in 2022--then by a Filipino team in 2023.
Despite all of this, year after year, US universities produce more high performers at the World Universities Debating Championship than any other nation. And it’s not even true that all of their top speakers are uninspiring!
Disclaimer on “equity”
This is not to say the American circuit has been a shining beacon of intelligent debate throughout the last decade. The 2021 US Universities Debating Championship was cancelled midway through due to a controversial decision to delay handling complaints about racism. Almost all tournaments have “equity teams” tasked with “ensuring debate is a welcoming environment.” In theory, these teams have frightening powers: they can expel participants from tournaments, censor “triggering” motions, and mandate apologies and “education.”
But equity teams generally don’t use most of their powers. Members of teams are almost always students who debate and judge on a regular basis. They are usually friends with many of the competitors. This creates strong social incentives to act reasonably. Equity teams always assume good intent and lean toward less punitive forms of mediation.
I have had a number of complaints raised against me. Equity teams have asked me to apologize and/or change my behaviour a number of times. In some cases (like the complaint I received for asking an opponent if they were stupid during a speech), I have happily done so. In others (like the complaint I received for asking if 18-year-old IDF soldiers can morally be held accountable if they are bystanders to war crimes without a trigger warning), I have declined. None of this has affected my participation in the activity. I am happy to trade off a tiny bit of my time and a tiny bit of extra politeness for an environment in which people can have spirited debates without personal animosity.
Why we should care about this at all
I understand that BP debate is a slightly convoluted, somewhat-closed-off corner of the world. I understand that when commentators reference “debate on campus,” this is not what they mean. But it is important to remember that debate on campus can look different from anxious half-empty classrooms and clips of Charlie Kirk speaking over mid-IQ students.
Li Shengwu’s ideas about making debate fairer and more intelligent substantially improved BP debate over a decade. I am hopeful that an increased focus on producing and preserving resources with similar potential (like Ryan Lafferty’s matter files) will improve it even more. More American schools should get on board.
British Parliamentary Debate
If you want a complete explanation of the rules, read them here. This is a brief summary of the aspects of BP most relevant to the review.
The format
There are four teams (two arguing for the motion, two arguing against) of two speakers. Each speaker gets seven minutes to speak. The speaking order looks like this:
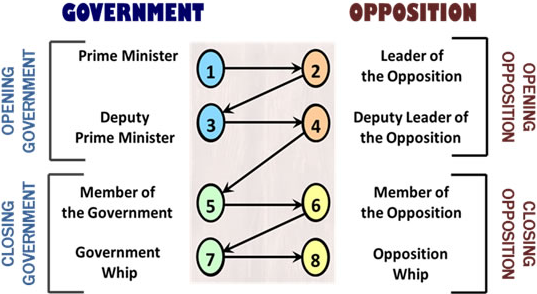
The silly names are relics of the actual British Parliament.
Between 1:00 and 6:00 of each speech, debaters on the opposing side (but not from the other team on their own side!) can offer “points of information,” or 15-second questions/challenges. The speaker can choose whether to accept or reject these (but can be nebulously penalized for refusing to take any).
All teams have to give arguments for their position, refute opponents’ arguments, and weigh the importance of their arguments against other arguments. Closing teams have to provide distinct arguments that don’t contradict what the other team on their side said (unless it was extremely obviously incorrect).
Motions
The topic of debate is called the motion. The beginnings of motions are almost always phrased in one of the following ways:
-
This House Would: this kind of debate is about implementing a policy or taking an action. The government teams have to prove it’s practically feasible and that it leads to better outcomes than alternative policies/actions. The opening government team gets to decide who the “house” is (it’s in their interest to pick something reasonable) and “model” what the policy’s implementation would look like.
- This House, as X, Would: Same as above, but the debate is from the perspective of a specific actor (e.g. “the CCP” or “a professional athlete”).
-
This House Believes That: More of a normative judgement than a policy.
-
This House Supports/This House Opposes: Exactly what it sounds like.
-
This House Predicts: Exactly what it sounds like.
-
This House Prefers: These debates will often set up an explicit comparison (e.g. world A over world B, action A over action B, etc).
-
This House Regrets X: Government has to prove that the world would be better off if X had never happened. Opposition has to prove the opposite.
Standard of knowledge for judges
Judges take on the perspective of the “ordinary intelligent voter,” a mythical creature who is intelligent and good at following complex logic, reads the front page and world section of some major international newspaper (without trying to memorize it), and doesn’t hold any biases toward any positions being debated.
Tournament format
Four teams face each other in a number of Swiss rounds (“inrounds”) (9 for some major competitions, 5 for most competitions, occasionally a different number). For each round, teams get 15 minutes to prepare their case (without the internet) after seeing the motion. After the debate, judges have 15 minutes to deliberate and rank the teams from 1-4 (as well as provide scores that practically range from 60-90 for each individual speaker). The deliberation is supposed to be done pairwise (i.e. judges compare Opening Government and Opening Opposition, then vote on who won between the two, then repeat this process for the other five pairings).
For each round, the team that ranks 1st gains 3 team points, 2nd 2, 3rd 1, and 4th 0. After the inrounds are done, the teams with the most points advance to elimination rounds (which are usually conducted in front of audiences). Individual speaker points are used as a tiebreaker when there are ties on team points.