The Signal and the Noise by Nate Silver
A Low-Probability Strategy
If you want to win a book review contest, consider doing something fun or dramatic. Or maybe take advantage of the preferential treatment Scott is giving to non-traditional and fiction books this year.
A non-fiction book about statistics is not a good strategy.
An even riskier strategy would be to take aim at the ACX website slogan, “P(A|B) = [P(A)*P(B|A)]/P(B), all the rest is commentary,” and suggest it may be time to retire that flag.

Riskier still, this review isn’t even about a new book. Nate Silver’s, The Signal and the Noise (tSatN) came out a dozen years ago in 2012. It got an updated preface in 2020, but mostly this is a stand-alone chapter as opposed to a revision that goes through and eliminates the many sections that have not aged well.[1]
Statistics should be a timeless subject. There can’t be anything new to learn in a reread … could there?
I would argue that the book’s age is a selling point, making it more relevant today. It’s not so old that the author is talking about the four humors, but it’s old enough to give us some parallax perspective about claims the author makes. As a product of its own time, we can see assumptions the author made that didn’t quite pan out. We can ask whether the book’s most aspirational claim pans out:
Bayesian analysis should be applied to every aspect of rational thinking.
About the Author: Nate Silver’s Claim to Fame
I remember when Silver first made headlines. In 2008, his forecast accurately predicted a win for Barack Obama, as well as the winners for every one of the Senate races. People talked about him like he was Nostradamus. He got TV appearances, launched a news/forecasting website, and even got a book deal!
Now, I want to be fair to Silver here. Later in the book, he is careful to point out that he doesn’t ‘call races’ so much as make probabilistic predictions about those races. I think Silver would concede that in 2008 he was being compared against very poor prediction models and he got very lucky.
On the other hand, he didn’t turn down his fame like Cincinnatus. He tacitly accepted the prophetic role people ascribed to him. That Faustian deal came with consequences. In the preface to the new edition, Silver is upset that people don’t understand probabilistic forecasting principles. Silver published multiple articles in late 2016 saying, “There’s still a 28.6% chance of Trump winning!” This fell on deaf ears. Moreover, his friends told him he was being a defeatist, giving false hope to political opposition. Silver’s frustration comes through in the 2020 preface. Why can’t people think probabilistically? He wrote a whole book about it years ago!
Why should he expect any other reaction? Silver projected a 71.4% probability of a Clinton win in 2016. Silver called it!
Except he didn’t call it, which was half the point of this section. The other half of the point seems to be that he … did call it? Or at least, that his projection hadn’t ruled out a Trump victory as many others had. It’s hard to hold consistent principles, especially when people are throwing money your way (more on that in the section on Fisher). This isn’t to say I think Silver ‘compromised’ any principles, as it is to say that he seems to have a blind spot for when and how to improve his probability estimates. If a probability estimate is above a certain threshold he counts it as a forecasting win, while if it falls below a certain threshold he counts it as an error that needs to be corrected. (No, don’t mention p-values to Silver.)
How lucky was Silver’s 2008 forecast?
In the book Silver doesn’t do this analysis himself, probably because it’s not hard to look up his predictions. Silver gave Democrats only a 15% chance of getting to at least 60 seats[2] that year. Although a 15% prediction will happen 15% of the time, it’s difficult to point at this prediction as having earned all the subsequent accolades.
The source of the future accolades was that whichever Senate seat was ahead in the polls was labeled as ‘ahead’ in Silver’s forecast, and then it was entirely a chance occurrence that all those races happened to resolve in the ‘right direction’ for Silver to be said to have predicted it. In other words, there were multiple degrees of freedom for declaring Silver’s forecast as having ‘got everything right’, depending on what you defined as ‘everything’ and what you defined as ‘right’. This is the problem of multiplicity in any post-hoc analysis we’ll get back to later.
Why belabor this point? Maybe it’s because I’m jealous of Silver and I’m trying to explain away his wild success in 2008. But Silver himself points out that he made significant adjustments to his model in subsequent races, including 2012 and 2016. Why improve on the model if it got everything right?
If you have a probabilistic model (which is the whole lesson of the chapter on election forecasting) you’re going to see probabilistic results. Any well-calibrated 90% forecast will be ‘wrong’ 10% of the time. Otherwise, it’s not well calibrated. Nate Silver already explicitly rejects the idea that his own claim to fame – getting every Senate race in 2008 correct – was anything other than just good luck.
Is there anything else to learn here other than what Silver has already put on the page? When we compare Silver's response to his 2008 prediction with his 2016 prediction, we see a different attitude. In 2016, Silver calls his 28.6% chance of a Trump victory a successful prediction.
What makes it a win for Silver’s model? He compares his prediction to those who gave Trump a 1% or 5% chance, pointing to his own articles saying that, yes, Clinton could still lose. He reminds readers that his forecast doesn't ‘call’ elections. It just gives a probability. I think this is accurate. But it's also slightly unfair. If some publication gives Trump a 5% chance of victory and then Trump wins, it's not accurate to say they ‘got it wrong’. After all, a 5% chance implies it will happen one time in twenty. If Silver wants us to think probabilistically, why does he spend so much of the preface to the 2020 edition failing to do just that?
I’d like to steelman Silver’s position as much as possible. He spends considerable time talking about political pundits who make no effort at accurate forecasts. He talks about arguing with pundits who can’t think probabilistically and round off a 5% chance down to ‘no chance’ in the way they talk. This is a fair critique of the pre-2008 political landscape. (And much of the current landscape.) These pundits made no attempt to calibrate their predictions, but Silver is happy to do it for them in the original text. They fail miserably. This is the right approach.
It’s an approach he doesn’t take in his updated preface for the 2020 edition. Instead, he calculates his win as being closer to the true observed value. Is this the right way to look at it?
Imagine a world where two Nates issue 10,000 forecasts. One is Nate Bronze, and the other is Nate Gold. Given all those forecasts, we calibrate both Nates’ predictions and how likely they are to be correct:
| Nate: | Prediction: | # Observed: | Calibration: |
|---|---|---|---|
| Bronze | 25-30% | 7,500/10,000 | 75% |
| Gold | 5% | 500/10,000 | 5% |
Bronze is biased and poorly calibrated. Meanwhile, Gold is perfectly calibrated. Now compare a situation like in 2016, where Gold predicted a 5% chance and Bronze predicted a 28.6% chance. Neither model predicted an outright ‘win’, meaning that some lower-probability event was realized either way. But which prediction was ‘right’?
Well, Bronze came closer to the observed value, but Gold was significantly better calibrated. If the point of asking the question ‘who was right’ leads you to learn some kind of lesson from this observation, the lesson you’re likely to learn is to trust the poorly calibrated, biased model more than the well calibrated one, or incorporate some bias into the well-calibrated model and make a good model worse.
Back to the real world: do I think Silver is better calibrated than the pundits who gave Trump a 1%-5% chance of winning in 2016? Yes, I do. Is Silver aware of the importance of calibration? He seems to be later in the book, though he doesn’t mention it here.
Then why bring up such a small error? Look, everyone can learn a principle and understand it, but it’s a different matter entirely to apply it consistently. That’s about habit and skill, not one-time learning or even memorization. Silver understands calibration, but here he defaults to the kind of quick and dirty analysis that he’ll return to many times in the book (favor the model that most closely matches the results, update based on ‘failed’ predictions). This bad habit biases him into learning a little too much from the noise in the data. And I don’t think this is purely an accident. At the heart of this is the Bayesian approach.
Bayes and the Silver Bullet
About halfway through the book, Silver introduces what he believes is a revolutionary way of thinking probabilistically: Bayes’ theorem. Many who read ACX will be familiar with the theory, but let’s do a short recap for anyone who is new. Much of the theorem can be explained with a simple equation:
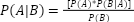
Let’s define terms.
P(A|B) is the posterior probability that A is true, given B.
P(A) is the prior probability that A is true.
P(B) is the prior probability that B is true.
P(B|A) is the posterior probability that B is true, given A.
This is all esoteric until we start looking at real-world situations. Let’s say you have a cancer blood test that accurately detects the presence of cancer 90% of the time. If someone has cancer, 90% of the time this test will come up positive, P(Positive|Cancer) = 0.9. That sounds good! But what about the test’s specificity? How often do we get false positives? Let’s say if a patient doesn’t have cancer, they’ll get a false ‘positive’ test result 5% of the time, P(Positive|No Cancer). Finally, let’s assume 1% of the population has cancer, P(Cancer).
If we get a positive test result, how likely is it that the person has cancer? To answer this question, we simply plug the variables into the equation:
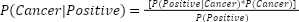
To calculate P(Positive) in the denominator, we’ll add together the probability of a true positive result the false positives of people who don’t have cancer: P(Positive) = P(Positive|Cancer) + P(Positive|No Cancer). Now we can plug this in with the numbers from above:
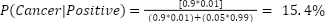
For every 100 patients who get positive results, slightly more than 15 will have cancer, while the rest were false negatives. This may be surprising. Despite this test having what looks like a high specificity, the large number of people you have to screen to find anyone with cancer means that the false positives dominate the results (84.6%). This is a powerful insight, and one that has had real-world consequences in recommendations for whether and when people should get cancer screenings.
But how accurate is it? We can find the rate of false negatives by giving the test to a bunch of cancer patients. The rate of false positives is a little trickier, but assuming we do a good screening job, we can give the test to a bunch of people we’ve carefully screened who don’t have cancer and figure out the rate of false positives. Now what about that third number: the rate of cancer in the population. How well do we really know that number? I handed it down to you as part of the hypothetical, but maybe that’s not good enough. You could look to the CDC or the NCI. Both will give you similar (but not the same) numbers. Global numbers are going to look different from US-centric numbers. Those will look different from numbers in your own state/city/family. How much does this matter? Say we take a dramatically different population and perform the same screening test. What’s the probability of a positive result if we’re looking at an enriched population where 50% of the people have cancer?
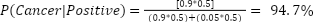
Suddenly this terrible test became highly specific. All we had to do was change our probability estimate of who has cancer. This is an important insight into Bayesian probability updates, and one we’ll come back to later. It matters what probabilities you feed into each part of the algorithm.
For now, let’s follow Silver’s logic of how we might use this equation to get around disagreements about what the baseline cancer rate is. Let’s say you and I disagree about the rate of cancer in the population. You think it’s 10% and I think it’s 0.01% - a thousand times less. We give the screening test to someone five times, and the test comes back positive five times. Assuming each test is independent, what’s the probability this patient truly has cancer? Since we both come to the table with different assumptions for the unknown probability, we’re going to get different answers from each Bayesian update. But watch how our estimates converge through serial applications of Bayes’ theorem:
| Result # | You | Me |
|---|---|---|
| Baseline | 10.0% | 0.1% |
| 1 | 66.7% | 1.8% |
| 2 | 97.3% | 24.5% |
| 3 | 99.8% | 85.4% |
| 4 | 99.9% | 99.1% |
| 5 | 99.9% | 99.9% |
This is the answer to solving differences of opinion. This is Nate’s silver bullet to reasoning in uncertainty, and a major theme of the book. If you just apply Bayes’ theorem to your problems, “all the rest is commentary”. But if Bayesian reasoning is the silver bullet, what monster is it created to slay? Enter RA Fisher and frequentist statistics.
Tilting at Windmills: RA Fisher
I don’t know what vendetta Silver has against Fisher. Maybe he found out the man slept with his grandma or disrespected a favored Revolutionary War hero. Perhaps it was Fisher’s sin of opposing Bayes. Whatever his beef, Silver’s judgment about both RA Fisher and frequentist statistics in general makes it impossible for him to see straight. Silver thinks frequentist statistics are outdated, complicated, and shouldn’t even be taught anymore. Why bother with Fisher when one simple equation from Bayes can replace all that complicated math?
So much of the chapter about RA Fisher is easy to critique because it’s objectively wrong or just outright slanderous. And not a little wrong. I have two stats textbooks on the shelf next to me. I can pull them down and point to specific places where Silver misrepresents basic principles of frequentist statistics. He claims that frequentists assume everything in life follows a normal distribution, basically accusing anyone employing frequentist methods of being oblivious to a world where any other kind of distribution exists. This is wrong.[3]
Or then there’s this gem:
The bigger problem, however, is that the frequentist methods—in striving for immaculate statistical procedures that can’t be contaminated by the researcher’s bias—keep him hermetically sealed off from the real world. These methods discourage the researcher from considering the underlying context or plausibility of his hypothesis, something that the Bayesian method demands in the form of a prior probability. Thus, you will see apparently serious papers published on how toads can predict earthquakes, or how big-box stores like Target beget racial hate groups, which apply frequentist tests to produce “statistically significant” (but manifestly ridiculous) findings.
Let’s set aside the weak man fallacy here for a second. (Are there no Bayesians who abuse statistics?) In Silver’s world, a frequentist builds a complex statistical model, decides on a p-value that would convince them that the model is correct (probably p < 0.05), then the thinking is done! If, after the experiment, the p-value is below the threshold the frequentist declares a victory for their hypothesis and moves on, never wondering whether this might be that 1 chance in 20 when they got their result by dumb luck. Never considering plausibility. Never even thinking whether there are other sources of error in the experimental design. Those poor dupes just mindlessly collect data and aren’t even allowed to consider the broader context.
In Silver’s world, frequentists don’t think probabilistically because the model has stripped that ability away from them. For frequentists, a hypothesis is either accepted or rejected, every data set is assumed to be normally distributed, and everyone relies on complicated equations they don’t understand to feed into a black box algorithm that does the thinking for them.
This is just manifestly wrong.
I’d like to defend the lowly p-value Silver loves to hate. Indeed, I’m going to defend the indefensible p < 0.05 threshold. I hope to show that not only are frequentists interested in much more than just some random threshold, but that properly understood it can become obvious – by analyzing a suspiciously low p-value – where underlying problems with an analysis are present.
In practice, p ≤ 0.05 should happen 1 in 20 times. Now my experience is in the field of basic biology research, so that’s what I’ll speak to here. Contrary to Silver’s story, almost nobody I know changes their mind about something based on a single figure – especially not one with a measly p < 0.05 threshold. You need to show that your predictions hold up under scrutiny from multiple angles, with different ways of testing the hypothesis, before anyone will be convinced.
Let’s consider a standard peer-reviewed paper. Say it has 4-6 figures. (We’ll estimate it at 5, and we won’t count the appendix.) If every one of these figures is using the same p < 0.05 threshold, the probability of all five figures independently agreeing through random chance goes to 1 in 3 million. Except each of these figures is broken up into 4-6 sub-figures, each at the same threshold. The probability of all these figures and sub-figures agreeing together in the same 1-in-20 fashion quickly becomes unlikely in the history of academic publications.
For a paper like this to be wrong by chance alone ought to be a fluke occurrence, one unlikely to ever be repeated. And yet many publications are later discovered to be wrong. And that’s the point: the research can still be wrong, just not because of random chance.
If we see something wrong after a mountain of experimental data suggests random chance isn’t at play, we can start asking deeper questions about how the experiment went wrong. (Something Silver thinks is impossible for the dull frequentist.) This might be any number of things.
Researchers make hundreds of decisions in experimental design, and each decision is built on a mountain of assumptions. Maybe the researcher repeated the experiment until they got the result they wanted (“I must have done it wrong”, or “it took me awhile to get the assay working correctly”). Maybe they had many degrees of freedom in which inputs/outputs they used to build their model on (“it’s not sensitive to X, but it is sensitive to Y”). Maybe they didn’t use a representative sample.
There are dozens of ways to screw up your statistics that have nothing to do with the probabilities. Sneering at every frequentist who cites a p-value ignores the source of the bad science happening here. It has us hyper-focusing on probability, distracting from the real biases in the research – a problem we should all want to fix. There is a whole literature about how to avoid mistaking signal when there’s only error present. The problem isn’t in the probabilities.
Battle of the Statistical Systems?
Silver and the Bayesian absolutists might opine here that they don’t need to do any of that fancy math or fiddle with complicated models and assumptions. They’re Bayesians so it doesn’t apply. They have one equation, and it’s effectively self-correcting. Frequentists dug their own hole, and they shouldn’t be calling on Bayesians to help dig themselves out of it.
I call BS. No Bayesian is churning out independent analyses of “discomfort related to lower back pain” from a 28-point questionnaire built off a 5-point Likert scale. If they are, and they’re not correcting their probability estimates for the fact that the scale is discontinuous, their already-garbage analysis is even worse. In practice, Bayesian inputs like P(A) and P(B) are often drawn from some statistical result previously generated by a frequentist. Leaning hard on ‘purity’ will just make you ignorant of whether the frequentists did their job right, or whether you’re updating from a dump of garbage statistics.
As I mentioned before, Silver seems to have a personal vendetta against Fisher. Indeed, he goes straight for the ad hominem attack: Fisher was an old holdout against the link between tobacco and lung cancer. He should have known better!
Why didn’t he know? Silver claims this is because Fisher’s tool – frequentist statistics – was blinding him to the truth. Let’s analyze that claim. What’s the probability Fisher believes there’s no link between tobacco and lung cancer because frequentist statistics suck? (As an exercise for the reader, go ahead and perform your own Bayesian analysis of the evidence for/against both sides. Given how strongly Silver makes the claim that Fisher’s stance on tobacco is driven by frequentist statistics – against all evidence – back-calculate Silver’s bias.)
Silver complains that Fisher should have known tobacco causes lung cancer. Why? Because this fact had already been demonstrated … by other frequentist statisticians!
Which explanation better fits the evidence?
- Fisher was blind to the obvious conclusions his frequentist colleagues had already accepted because his frequentist statistics led him (and somehow not them) astray, or
- Fisher didn’t want to believe because he liked to smoke and got paid by the tobacco companies
Silver not only rejects all of Fisher’s contributions to a complex field of analysis – to the point of outright distortion – he goes on to reject the entire field of frequentist statistics.
Why?
I suspect Silver’s background informs his world view. Nate Silver used to be a successful[4] poker player. He used his statistical prowess to become a successful baseball statistician. He then used that same mind to create a successful business making political predictions. What do all these things have in common – in the world of statistics? They’re all games of chance, sure. But they’re all a particular kind of game:
- Zero-sum
- With definite winners and losers
- Where results are announced objectively at defined timepoints
In elections, baseball, and especially poker you can make a prediction and put money down on that prediction if it differs from someone else’s prediction. Later collect or pay out and see whose model fit the real scenario. There was one right answer, and everyone empirically knows what that answer was. It’s not up for debate. This is the world Silver comes from, and it’s the world all his statistics live within. The problem for Silver, then, is that this does not describe most of the world outside of his narrow specialty.
Most questions aren’t first approximations of a zero-sum game. Many questions will never have a definitive answer even when they are zero-sum. (Was SARS2 leaked from a lab? Does increased government surveillance prevent terrorism? Did bailouts help or hurt during The Great Recession?)
Many other questions aren’t zero-sum at all. “What was the cause of World War 1?” Much of life is multi-causal, poorly defined, and continuously evolving. In addition to thinking probabilistically, we need to be able to think in terms of share or contribution. Too much analysis focuses on digital outputs to an analog world. Even a percentage estimate revolves around a digital yes/no. How do we get away from this kind of thinking?
Now, I’m not an evangelist for frequentist models. The only reason I’m defending them is because I believe they’re sometimes useful (just as I think Bayes’ theorem is sometimes useful). But I don’t think the solution to the problems above is found in frequentist models. Whether Bayesian analysis can be adapted to this kind of problem isn’t something Silver’s book considers either. Instead of preparing his readers to live in a multi-causal world where ambiguity reigns, Silver encourages his readers to narrow their worldview to the kind of problem he seeks out: find the kind of ‘bet’ you can put money on. Silver’s book implicitly[5] encourages the reader to ignore everything that can’t be transformed into this kind of game.
In Silver’s defense, fuzzy, multi-causal questions may never be answerable. Instead, we might focus on a question that can be answered like, “Did minimum wage law X impact employment in industry Y?” Then we can update our models based on this new information.
This approach feels a little like the drunk man looking for his keys under the lamppost – not because that’s where he lost them, but because that’s where the light is. This might be a good strategy for some questions, but we shouldn’t fool ourselves into thinking we can substitute these biased specifics for the general answers we want to find.
This is the point where Bayes pops in to muddy the water. A Bayesian will combine each of those specific answers, plug them into the equation as updates, and stumble toward a strong prior about what the ‘true’ answer is – based on the evidence! But there’s an assumption here, that we can break the multicausal system down into component parts, study them piece by piece, and in so doing understand the whole. Yet most complex systems don’t function in pieces the same way they function as a whole, with interactive moving parts.
Silver has made a lot of money doing the kind of reductionist work he recommends in his book. If you want to make a lot of money using Silver’s approach, he’s on solid ground recommending you do so. But that’s not the same as using Bayesian methods to answer complex questions. If you want to use Silver’s approach, first make sure your situation is built for successful Bayesian analysis.
Is Bayes’ approach fit-for-purpose?
This is where Silver and other advocates for expanding Bayesian logic will pounce and declare that the Bayesian really shines in this environment. After all, if there’s a disagreement that requires disparate people to come together to discuss all the evidence and gradually approach a conclusion, Bayesian mathematics is made for this moment! Even if everyone starts out with different priors, Silver claims, so long as we all assign the same probabilities to updated information, everyone will end up pretty close to the same conclusion – even if that conclusion is that we need more evidence to be certain one way or another.
That’s great in theory, but in the real world it’s rare that everyone agrees on probability estimates. This brings up the big question for the Bayesian absolutist to answer: why doesn’t everyone assign the same probabilities for B, A, and B|A? After all, Silver claims,
If the philosophical underpinnings of Bayes’s theorem are surprisingly rich, its mathematics are stunningly simple. In its most basic form, it is just an algebraic expression with three known variables and one unknown one. But this simple formula can lead to vast predictive insights.
Four variables and three of them are known? That’s easy! This isn’t some complicated frequentist model with lots of assumptions. It’s a simple matter of plug and play.
This is true for many of the simple cases Silver champions in the book, but in most real-world situations applying Bayesian logic makes our job harder, not easier. Let’s take a simple example, where frequentist statistical reasoning makes the conclusion obvious and immediate, but Bayesian analysis muddies the water to the point where it’s nigh impossible to understand.
When my wife was pregnant with our first child, she got morning sickness. Her doctor prescribed Zofran, and the morning sickness went away. Same with our second child. With our third child, the doctor refused to prescribe Zofran because it “might cause birth defects”. When I heard this, I went to PubMed and looked up the research.
The authors did indeed find a signal (increased number of cardiac birth defects in the treatment population vs. controls). Interestingly, a second study failed to find the same signal. Now, a Bayesian might have started off with a low prior for birth defects, but thinking probabilistically they would also want to set a low threshold for action[6]. This Bayesian would likely have ‘updated’ in the same way our physician did, recommending against Zofran with the first paper. But then comes the more interesting question: should the doctor have updated fully against Zofran with the second paper, or should they have required multiple papers showing no link before being comfortable prescribing Zofran for morning sickness? Unfortunately, the algorithm doesn’t give us any guidance for where to set the thresholds, and one doctor might set a threshold differently from where another might. That’s fine, since we’ll eventually end up in the same place. Let’s set some probability estimates and let Bayes’ theorem do the work for us:
P(positive paper for defects|defect exists) = 95%
P(negative paper for defects|defect exists) = 5%
| Result | Doc #1 | Doc #2 |
|---|---|---|
| P(defects from Zofran) | 10% | 0.1% |
| Positive | 65.5% | 1.9% |
| Negative | 6.8% | 0.2% |
| Negative | <0.1% | <0.1% |
We got to the ‘right’ place, after just two follow-up papers!
Well, maybe.
I’m sure the authors of the positive study will argue why the negative studies were done wrong, and vice-versa. We’ll get into a debate about technique. One side will debate whether the prior and posterior probabilities were set right. In the end, half of the doctors will still be refusing to consider Zofran safe after a dozen papers negative for birth defects, while others would still be prescribing it after at least a few positive papers. The whole thing will devolve into a Bayesian mess because people are allowing their priors to not just define P(A|B), but also how they interpret new data, i.e. P(A) and P(B). While everyone debates the specific details of each study and how much credibility they should assign them, what we’ll end up with is probably something closer to this:
| Result | Doc #1 | Doc #2 |
|---|---|---|
| P(defects from Zofran) | 10% | 0.1% |
| Positive | 78.5% | 0.2% |
| Negative | 72.8% | <0.1% |
| Negative | 72.1% | <0.1% |
| Negative | 68.4% | <0.1% |
Let’s talk about what’s not being done in this analysis. To do that, we’ll let the frequentists back into the discussion.
That first paper – the one that identified an increase in birth defects – found their signal as part of a retrospective analysis. Their hypothesis was that Zofran would cause teratomas. It didn’t. But the authors claimed a ‘statistically significant’ increase in birth defects. Is that real?
No, because of the problem of multiplicity.[7] A frequentist setting up an experiment knows they must first calculate their statistical power to answer the question. Since there’s no way to power an unknown amount of multiplicity, the frequentist automatically identifies the post-hoc analysis as a different kind of evidence. It’s good for hypothesis generation, but it’s qualitatively different from predetermined experimental evidence.
What the frequentist sees is that the first paper failed to find evidence to support their original hypothesis, “Zofran causes teratomas” while generating a new hypothesis, “Zofran causes heart defects”. Knowing that the first paper’s newly generated hypothesis was almost certainly noise (though not conclusively so since there’s still a small probability of Type II error) casts the second paper in a different light. The hypothesis made a prediction. The prediction failed, so it is rejected (though we’ll continue to collect additional evidence and gain more confidence in that rejection).
Notice how much more difficult this problem became when we ignored basic frequentist principles. Seeking only to apply cumbersome Bayesian updates to every situation led to us chasing noisy patterns forever. I can hear the hardcore Bayesians grumbling about this point, “Fine, we’ll take the lesson on multiplicity into account as we make our probability estimates. We wouldn’t assign the same weight to each piece of evidence anyway. That doesn’t mean we need to take anything else from Fisher – that evil shill for Phillip Morris.” The problems for Bayes only get worse from here.[8]
Against Universalizing Bayesian Thinking
From Silver’s telling, even if everyone starts out with different priors, all Bayesians willing to calculate serial updates will converge around the same conclusion, given enough evidence. If we observe wide disagreement, we don’t have enough evidence.
Scott’s recent review of the lab leak/zoonosis debate revealed a bizarre result when Bayesian principles were taken to their logical conclusion. Instead of Bayesian math converging on a single answer … well everyone kind of went their own way.[9] What went wrong in the Rootclaim debate? Scott gives some insight that should cause any Bayesian serious reflection (emphasis mine):
Rootclaim asks: what if you just directly apply Bayes to the world’s hardest problems? There’s something pure about that, in a way nobody else is trying.
Unfortunately, the reason nobody else is trying this is because it doesn’t work. There’s too much evidence, and it’s too hard to figure out how to quantify it.
If Bayesian analysis doesn’t work, the last reason we would expect is because “there’s too much evidence”. How did the solution become the problem?
The last part of that quote hints at why, “it’s too hard to figure out how to quantify [the evidence].” The issue isn’t that Bayes was wrong. It’s just being applied to the wrong set of problems: namely every problem. The equation isn’t built for that.
Look again at it again:
What does it really mean? What is a posterior probability? What is a prior probability? “In theory” these questions should be easy to answer since we have all the observations. That’s not what happened in the Rootclaim debate. Not only did the two debaters present different probabilities for each event, so did each of the judges. And so did Scott! And honestly so did everyone else who tried their hand at it. Far from being objective, each of these variables proved subjective.
Bayes’ theorem works great if the prior and posterior probabilities are empirically derived values. But if we don’t know those – if we’re guessing, estimating post-hoc, adjusting for ‘model uncertainty’, etc. – the only thing we can get from a Bayesian analysis is an undeserved sense of confidence.
For many questions, an accurate application of Bayes’ theorem is impossible, no matter how much cheerleading we do about the benefits of the Bayesian approach, because we can’t complete the equation. If this is true of a formal attempt at the Bayesian approach like in the Rootclaim debate, what can we expect from informal applications of Bayes’ approach?
What does Silver really mean when he says “Bayesian”?
Given that Silver claims ‘Bayesian thinking’ is a nigh revolutionary way of seeing the world, it’s a little odd that the formula, P(A|B) = [P(A)*P(B|A)]/P(B) makes few actual appearances in the book. With how much Silver wants us to do Bayesian analysis, why isn’t the formula calculation showing up on every page – or even once a chapter? I think I have more calculations in this review than Silver had in his whole book.
I think this is because Silver has internally redefined what ‘Bayesian’ means. Silver is good with statistics and statistical thinking, but he has expanded his model of what counts as ‘Bayesian’ too broadly. Silver talks about things like Google’s A/B testing and chess programs as “a very Bayesian process”. But what does Silver mean when he claims this is Bayesian? He clarifies, “Google is always at a running start, refining its search algorithms, never quite seeing them as finished.”
That’s … not strictly Bayesian. It’s certainly good practice, but it’s not something that can only be implemented when you put precise numbers on each of your probabilities.
Silver picked an unnecessary fight with frequentist statistics. Any lesson about probability, no matter how general, gets cast as part of this faux battle between the righteous Bayesians and the tyrannical frequentists. His model for how frequentists view the world is weird. He frequently inveighs against their statistical models, claiming that they do nothing but make one-off declarations of “truth” that shall stand for all time as peer-reviewed ambrosia handed down from the gods:
Essentially, the frequentist approach toward statistics seeks to wash its hands of the reason that predictions most often go wrong: human error. It views uncertainty as something intrinsic to the experiment rather than something intrinsic to our ability to understand the real world.
Think about this claim: frequentist statisticians seek to ignore human error as a source of bias. Really? To be fair, it seems Fisher picked this same fight first, but there’s no reason we have to adopt the bad priors of earlier generations. Why do we have to accept this ancient battle line, where we either reject Fisher or Bayes, and then ascribe every statistical sin to “the other side”?
And there are sinners who believe this kind of garbage about: the scientific method, peer review, published papers, etc. But they predate RA Fisher, and these transgressions aren’t persistent because people learn to calculate a p-value. There will always be statistical sins, but Bayes isn’t going to absolve you of those sins. You have to work on that yourself.
It Doesn’t Have to Be This Way
I do think books like tSatN help with that. Maybe Silver felt the need to lean in so hard at overcorrecting, using spurious connections to Bayes theorem to popularize ideas like ‘probabilistic thinking’, because of people who want to think of statistics as being as error free as a mathematical equation. (I would argue that the earlier work of John Ioannidis had a greater cultural impact inside and outside of academics, among many others. And indeed, more good work on what it means to learn through the scientific method continues to be done.) Yes, we should learn about statistical sins to avoid them, but let’s not fool ourselves in the process into committing new sins.
An allegory: My son loved his bike and became a confident rider long before I got around to removing the training wheels. On one hand, his hard riding bent those tattered wheels back, so that most of the time he wasn’t even using them anymore. On the other hand, once I finally did take the training wheels off, he was initially scared to ride his bike. He had little confidence, and made broad turns instead of obvious and easy ones.
It’s been a dozen years since tSatN came out. When I first read it, it did help reinforce probabilistic thinking and some other good rational practices. But it did so in a way that felt like training wheels on a bicycle, forcing artificial restrictions. It wasn’t until recently that I even realized they’re still there. It’s time to take off the training wheels.
I think Bayesians have mostly bent back the restrictions of a purely Bayesian approach, which they hardly even use anymore. They’ve developed some good habits that they may think of as ‘Bayesian’ but aren’t really tied to Bayes’ theorem in a meaningful way. They ‘think probabilistically’, by assigning a number to their confidence (sometimes even writing it down and sharing it with others, sometimes going so far as to calibrate their predictions).
But they[10] also have some bad habits of estimating prior probabilities post hoc or in other invalid ways. They do a quick and dirty ‘Bayesian’ estimate, or sometimes even formally plug the numbers into a spreadsheet, and they get a false sense of precision. They lean a little too hard on the training wheels.
We can do better than applying narrow statistical lessons overly broadly. We don’t have to overfit our models. Let’s return to that ACX website slogan “P(A|B) = [P(A)*P(B|A)]/P(B), all the rest is commentary.” I used to like that slogan. I used to think it was clever. Now, not so much. Sometimes, Bayes’ equation gives powerful new insights. Most of the time it is the wrong model. It might even be time to move the phrase, “all the rest is commentary” to the ‘mistakes’ page.
The Bayesian training wheels are overly restrictive. They prevent us from considering the contours of frequentist statistics. And whether you agree with the frequentists or not, they’re not going anywhere. Their methods will continue to be used. (And continue to be abused by those who poorly understand them.) Let us reject Silver’s mandate that we toss whole branches of statistics. By embracing the entire world of statistical analysis, we can know what tests to use (and not to use) for each situation. We can be more honest about what we know and about what is still unknown. And maybe we’ll get a little better at distinguishing between the signal and the noise.
The Signal
Having spent so much time tearing down what Silver considers his most important point, you might think I hate everything about this book. Quite the opposite. I think there’s a lot of wonderful material in this book. If anything, a careful reading of tSatN will provide a masterclass on how difficult it is to consistently apply good statistical principles. Silver outlines dozens of principles and important nuances. Here are a few examples:
-
Don’t overfit[11] based on past cases.
-
Low-probability events sometimes[12] happen.
-
Don’t trust a forecaster with a poor record.
- Corollary = don’t trust highly precise forecasts with records of low precision.
- Corollary = know your forecast’s range of uncertainty.
-
Change your forecast when the evidence changes.
-
Beware the comprehensive model and the quick fix.
-
Patterns are not the same thing as signal.
-
More data = more noise.
- Corollary: The hypothesis-free approach is prone to hallucination.
-
Averages may conceal complexity.
-
Don’t overlearn from computer[13] model outputs.
-
Don’t just extrapolate a trendline.
-
Sometimes people react to a prediction, changing the outcome.
-
Sometimes you’re too emotional to think probabilistically – it’s okay to walk away.
I’ve flagged a few of these where Silver failed to follow his own advice in the book. I don’t think this is because Silver isn’t good with statistics. He’s made millions of dollars over the years proving otherwise. If Silver is making mistakes despite being particularly good, what does that say about the rest of us?
The project Silver is advocating for is a lifetime achievement. If Silver is still working on it after writing a book about statistics, you’re not likely to get there from a casual once-over of this book.
Okay, so yes or no to reading the book?
I’ve seen atheists make fun of religious believers for ceremonies, rituals, and preaching in which the believer repeats a process over and over with very little ‘new material’. What’s all that performance getting you? How many times are you going to reread the psalms before diminishing returns set in? But the point of preaching is different from that of teaching. It’s not to imbue some new bit of knowledge, so much as to remind the audience of principles they already committed to live by. The ritual brings a renewed sense of the importance of strictly adhering to those principles.
I think this innovation can and should be stolen from religious traditions and applied to mastering disciplines like statistical nuance and scientific rigor. It’s not enough to read about various forms of selection bias once. Mastery comes from reviewing them over and over, testing them out, and returning to the material again. When Silver talks about getting “less and less and less wrong” he does so in the context of simple Bayesian updates, but I think when it comes to statistics the real lesson isn’t a simple algorithm so much as a devotion to steady improvement over time.
Devotion to steady improvement is the real subtext of Silver’s book, and the lesson that comes through on every page, and in every statistical nuance he outlines. That’s a lesson worth learning … and then returning to again and again to consistently get it right. So go ahead and read The Signal and the Noise. Then read it again.
Footnotes
- ↩
“The epidemiologists I spoke with for this chapter – in a refreshing contrast to their counterparts in some other fields – were strongly aware of the limitations of their models. “It’s stupid to predict based on three data points,” Marc Lipsitch told me, referring to the flu pandemics of 1918, 1957, and 1968. “All you can do is plan for different scenarios.” If you can’t make a good prediction, it is very often harmful to pretend that you can. I suspect that epidemiologists, and others in the medical community, understand this because of their adherence to the Hippocratic Oath. Primum non nocere: First, do no harm. Much of the most thoughtful work on the use and abuse of statistical models and the proper role of prediction comes from people in the medical profession. That is not to say there is nothing on the line when an economist makes a prediction, or a seismologists does. But because of medicine’s intimate connection with life and death, doctors tend to be appropriately cautious. In their field, stupid models kill people. It has a sobering effect.”
- ↩
While this is technically true, the reality is that the whole process was messy. Two senators had to fight legal battles before getting seated. By this time, one of the MA senators (Robert Kennedy) passed away. Massachusetts held a special election, where a Republican won. We’ll get into this more later, but this demonstrates how even an ‘accurate’ prediction of “Democrats will win 60 seats in the 2008 election” may not answer the question we really want to know, which is “Will Democrats win a filibuster-proof majority in the Senate?” The real world is messy.
- ↩
Fisher and his ilk don’t assume a normal distribution is some kind of universal law. They say, “where a normal distribution is assumed by the statistical test you’re using, applying any other distribution will yield the wrong results.” This is an important point stats professors across the globe try to drill into their students’ heads – often to no avail. Indeed, Silver’s casual dig against those darn frequentists and their ‘normal distribution assumptions’ doesn’t add to the real discussion that needs to happen here. Sure, you can assume a distribution, but there are tests to make sure you’re not making false assumptions of your data. (A test dreamed up by those darned frequentists? Oh no!) People should know about this. There are a lot of things they should know about their data before doing whatever random statistical test gives them an answer they like.
Was your survey based on a Likert scale? You’d better not use statistical tests that assume a continuous distribution. Students make this mistake all the time, because they don’t know there’s a difference. None these lessons are coming from Silver.
I’m not saying Silver should have written a statistics textbook. I’m saying that dismissing the textbooks that have been written is only going to compound the problem of statistical illiteracy that produces so many errors in both academic and everyday practice.
- ↩
Silver might object to the word “successful” here. He discusses in the book how difficult it is to make money at poker. He suggests he was never more than a middling player at best, and that once regulatory agencies drove away the big fish, it took him a few months to realize he was effectively the new fish the other players were feeding on. I’m certain Silver could beat me at the game, though.
- ↩
Not explicitly, but Silver spends a lot of time trying to get readers to retrain their minds and ‘think probabilistically’, by which he means adapt strategies like the betting heuristic.
- ↩
Nassim Nicholas Taleb does a good job of talking about this kind of uncertainty. Silver mentions his work in tSatN, but I don’t think he has the same grasp of the material that Taleb does. I recommend Taleb for understanding how to appropriately react to unknown risks, tail-end risks, survivorship bias, and a host of other ideas.
- ↩
In a clinical trial, you collect hundreds of different data points. And of those hundreds of data points, some are open-ended, like “have you experienced any adverse events?” If someone feels dizzy or has frequent headaches, those are reported. That’s good practice! Let’s say your drug causes a slight decrease or increase in blood pressure. We’ll see that in patients who get dizzy or get headaches reporting symptoms more frequently than placebo (on top of the frequent blood pressure checks). Some side effects can only be discovered after people start taking the drug, and this is how we discover them – by looking for patterns in the data.
But as tSatN points out, it’s easy to see signal when there’s nothing but noise. This is compounded in a pregnancy study, where the outcome of every pregnancy is followed to its conclusion, dramatically adding the number of potentially noisy data points dutifully collected by the researchers. Each new data point increases multiplicity and the possibility of seeing patterns where only chance is present. This isn’t just a problem with defining a p<0.05 threshold, and indeed the frequentists seem to have figured this part out. The Bayesian who refuses arbitrary definitions like p-value still has to figure out whether they’re looking at signal or noise. The typical Bayesian rejoinder, “we’ll just make more observations” is ignoring the most important part of the signal here.
If I make hundreds of observations, including open-ended observations with an uncountable number of chance coincidences, I’ve assured myself that I’m going to find some pattern in the noise. There may be signal there, but there is certainly noise. And if I’m not careful, I’ll waste all my time chasing noise.
- ↩
I’m not claiming Bayesian principles are never applicable. But Silver’s dismissiveness about Fisher and all principles of frequentist statistics makes it clear that he thinks everything but a Bayesian approach should be abandoned. Consider which of these two positions makes more sense:
- Silver’s claim that there’s one equation that effectively eliminates a major branch of the field – one that developed far more recently, and on which thousands of scientific papers and discoveries have relied.
- My claim that statistical models all have in-built assumptions. They apply only in situations where their assumptions can be demonstrated to hold. No one model is applicable in all situations. I’m sure there are even some situations that defy all current models.
- ↩
To be fair, Peter and the judges all updated to the same direction, which is what a good Bayesian would predict. But they did so after assigning significantly different probabilities to many different questions, such that Peter (the debate’s winner) ended up many orders of magnitude away from the judges, while Saar (the debate’s loser) was orders of magnitude in the opposite direction from the judges. Good Bayesian logic dictates this should only happen because everyone started off with wildly disparate priors. But the opposite is the case. They started off closer together than they did at the end. Bayesian logic isn’t supposed to cause divergent conclusions.
- ↩
I counted myself in this camp until quite recently. I’m not claiming to be rid of bad statistical habits.
- ↩
Silver attributes the financial crisis to ratings agencies failing to consult international data. He calls this a lesson on your data being “out of sample”, but Silver only knows what lessons to take because he knows what would have ‘fixed’ the sample. The lessons ratings agencies would have learned had they consulted international data ex ante are unlikely to be the specific ones Silver points out. There were many other factors/incentives that would almost certainly have led to the housing market crash no matter how ratings agencies built their models.
This is a repeating theme in the book. Silver will adjust his model, based on the current crisis, to match what he knows today. But he only knows what data to consult – and when it’s salient – because the failed prediction lives in the past.
- ↩
Silver calls Pearl Harbor a failure of prediction, but I don’t agree. The reason to discount it as highly improbable is that it was a really bad strategic move for the Japanese. It should have been considered low probability, based on what was known at the time. Meanwhile, the US was making the Japanese war effort more difficult, so sabotage was a much higher probability event.
Am I falling victim to past-casting here - considering things that wouldn’t have been obvious to the people at the time? I don’t think so, but I’m open to being proved wrong. What did the Japanese have to gain by an attack on the US, especially in 1941 – given what was known by the US at the time? US industrial capacity far exceeded that of Japan. The US had domestic oil production, which was not the case for Japan and was a tool the US used to apply pressure against Japanese aggression in the region. The US had increased their war production capacity for Europe but wasn’t directly engaged in the war against Hitler.
All these facts combined suggested it would be virtual suicide for an expansionist power like Japan to seek a direct confrontation with the US. It would be like a scrawny second grader going up to the biggest sixth grader on the playground surrounded by their friends and giving that kid a sucker punch. Would the sucker punch work? Sure, but then there would be consequences. And that’s exactly what happened for Japan.
- ↩
In the section on computers that play chess, Silver exhaustively tells the story of how Kasparov played his matches against Deep Blue by specifically preparing for computer weaknesses in mind. Then, when the computer made a random move instead of the expected one, Kasparov interpreted this as ‘genius’ instead of seeing it as a bug the programmers had missed. Later, Silver discusses outputs of computer systems, and suggests that reading anything from them other than output (including anything approaching what I would call “theory of mind”) is in danger of over-reading computer algorithms. This is a fascinating take, and probably not something Silver would agree with today after many of the advances in AI that result in a less algorithmically driven approach to much of machine learning. At the least, I think it’s premature to conclude that AI will never be able to “think” in a way other than strictly algorithmically. While it’s still easy to see eccentricities in computer outputs as errors in code (e.g. the many-fingered hands of early AI image generation) the question of what is genius and what is a software bug is becoming much more difficult. Might Silver’s heuristic be overfitting?