Why Greatness Cannot Be Planned, by Joel Lehman and Kenneth Stanley
Dissolve yourself for a second.
Let’s say you are trapped in a robot in a maze. You want to reach the end of the maze, where you hear they are handing out free cookies. How do you move forward?
You're trapped in the robot, so the only way to move is to program the robot with a binding dogma. One algorithm to follow above all others. What strategy should you use?
Well, one strategy you might use is something called objective search. This means you measure your robot's distance to the objective, and take any path that reduces that distance. We know what our objective is, and we set out to achieve it. On the surface of things, this seems like a good strategy. After all, we want to go straight towards our goal as fast as we can.
In their 2015 book Why Greatness Cannot Be Planned, Joel Lehman and Kenneth Stanley (henceforth, L&S) spend the entire book showing why this plan is going to fail. Using objectives as a guide will fail you in this maze, and they will also fail you in life, and they will also fail you for nearly every meaningful task that you set your mind to.
To explain why, let’s stick with the maze for now.
There’s one immediate problem. If we're in a maze and we can't see the objective, how do we measure our distance to the objective? To get around this, let's assume that we're in a glass maze, meaning that we can see where the final objective is.
We’ll mark the robot we're trapped in with a cool little circle, and the sweet cookie treasure we're hunting for with an 'X'. Here’s a maze:

Using objective search, our little circle dude will just run into the wall and get stuck. It can never reach the objective, because it has to go away from the objective before it goes towards it.
In animal psychology there is a family of experiments called the detour paradigm. You put some food in front of an animal, but block it with a transparent fence. The animal must find a way to go around.
You can use the ability to detour away from food as a crude proxy for intelligence. Chimpanzees and dogs generally succeed at these sorts of tasks, while chickens find the task harder. It’s unintuitive. The animal has to move away from the target so it can get closer to it.
What sort of algorithm would solve the above maze? Well, one option is to tightly map our algorithm to the maze:
- Go right until you hit a wall
- Go up until you hit a wall
- Go left until you hit treasure
Great. Here's another maze:
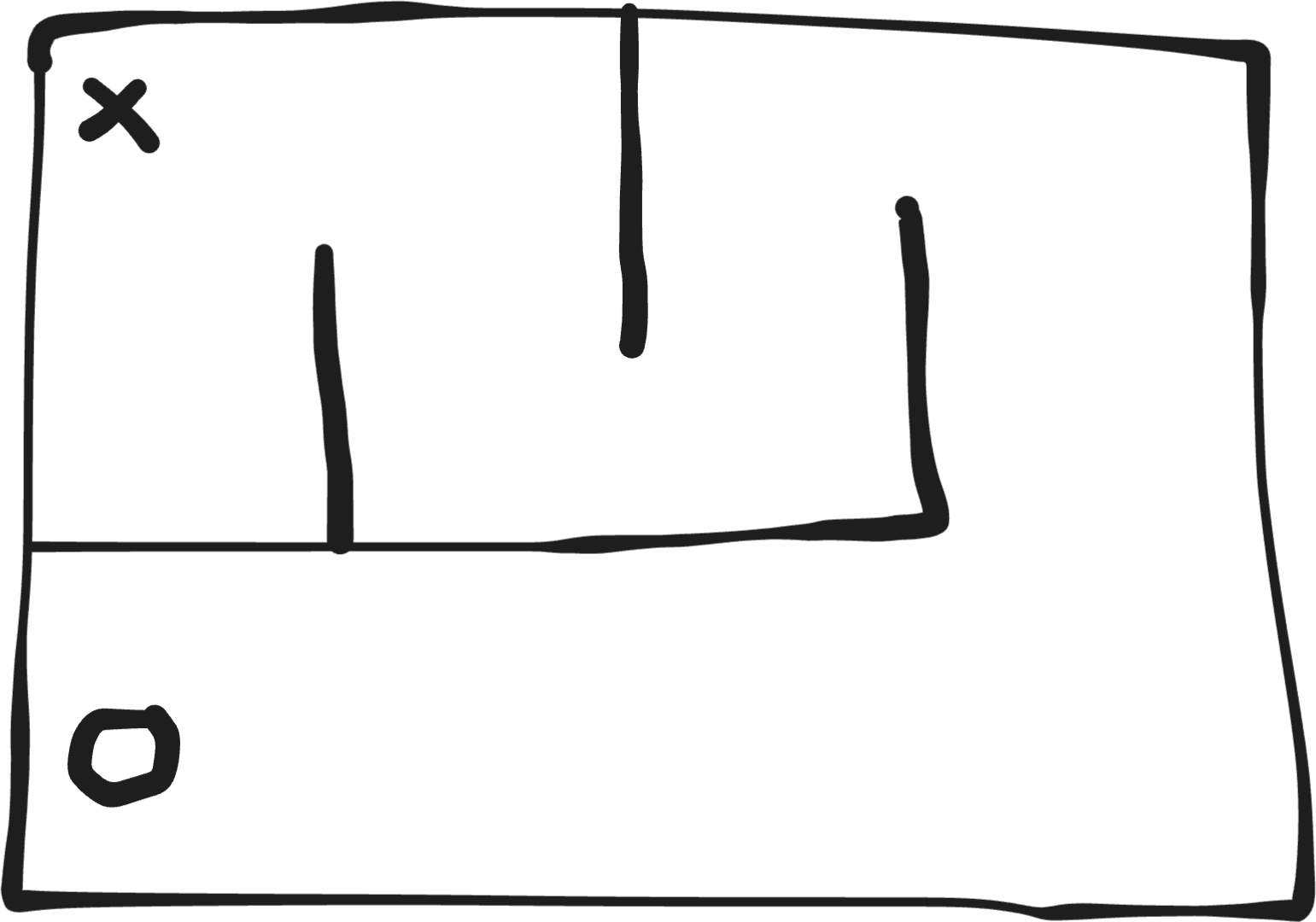 This is the problem with pure objective search. For any objective which is meaningfully challenging, the path to get there is not simple.
This is the problem with pure objective search. For any objective which is meaningfully challenging, the path to get there is not simple.
In the real world, relying on objectives can also begin to collapse the utility of the benchmark that you were using in the first place. A classic example is Goodhart's law: "Any observed statistical regularity will tend to collapse once pressure is placed upon it for control purposes."[1]
This is a common regularity. Try Campbell's law: "The more any quantitative social indicator is used for social decision-making, the more subject it will be to corruption pressures and the more apt it will be to distort and corrupt the social processes it is intended to monitor." Or Lucas' critique: "Historical statistical relationships will not hold in response to policy changes, because people alter their behaviour in response to the policy".
As we'll see, any form of search strategy has fundamental strengths and constraints, and it's important to be aware of them.
Something Old, Something New
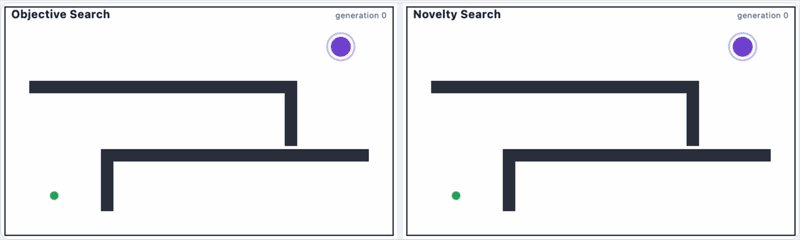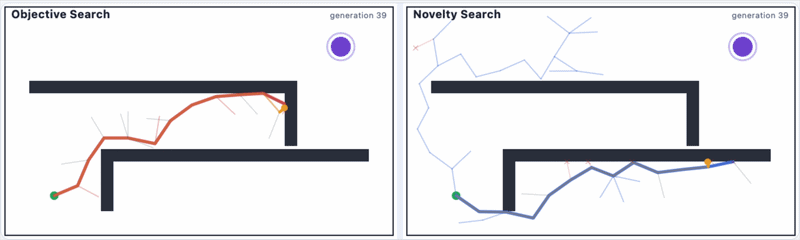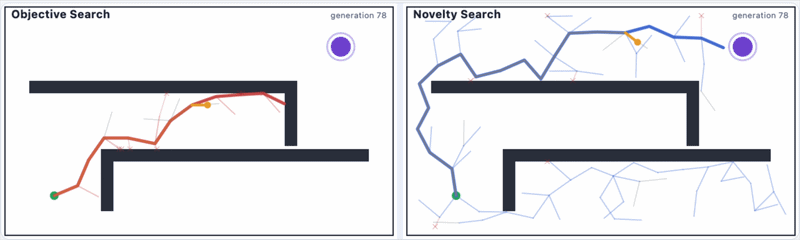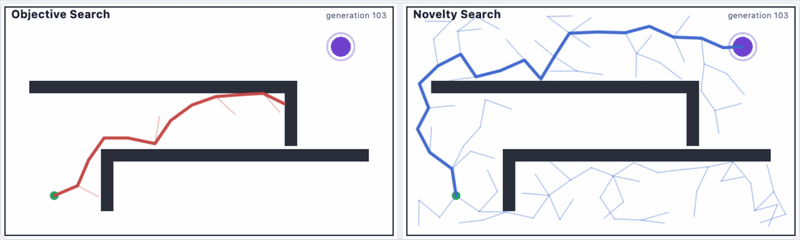
L&S present a solution to this problem: novelty search. Here, we tell our robot to look for new areas.[2] Any time it goes to a new place, it gets rewarded.
Here's a side-by-side comparison of how that might look:

Even if we make changes to the maze, novelty search still works, as you can see:
 [I made the code for these GIFs.]
[I made the code for these GIFs.]
Novelty search not only does better than objective search, but it also finds spaces in the grid that objective search would never dream of looking at.
L&S argue that any ambitious objective is by its very nature deceptive. If we could see the path to an ambitious objective and it was easy to reach, it wouldn't be ambitious.
Most of the things we want to achieve in the long-term are ambitious. They are hard in critical ways. We cannot immediately intuit how we should go about achieving them.
An obvious counterexample to their argument might be something like the moon landings, which seem like an ambitious objective with known goals. But the important idea here is not that objectives never work. L&S allow that modest objectives work, and they work all the time.
But when you are setting distant goals without obvious steps to them, then problems become both ambitious and deceptive again. There were significant unknowns in the NASA space programme, but many of the steps could be broken down and decomposed into engineering problems. That wasn’t the case if you were alive in the year 1865, where Jules Verne (not entirely seriously) suggested using a giant cannon to blast humans into space.

[Projectile trains for the Moon, Jules Verne. Source.]
L&S argue that a lot of important problems that we care about are ambitious and deceptive, whether that’s finding an architecture that might replace the transformer, or your goal of becoming a professional crocodile tamer. There isn’t one obvious path with clear steps along the way.
What sorts of ambitious objectives do L&S use as examples?
“To name a couple of very significant ones, natural evolution and human innovation also proceed without any final objective, as we’ll see... The problem is that the stepping stones to intelligence do not resemble intelligence at all. Put another way, human-level intelligence is a deceptive objective for evolution.”
So how do you reach an objective that is ambitious and deceptive? Well, we don’t know. That's kind of the point. But the path to most objectives involves what L&S call stepping stones. They define these as "portals to the next level of possibility". These are small jumps which open up new opportunities for places we can jump to.
Imagine a frog hopping across a foggy lake. It has a choice of a few lily pads it can hop to in order to get across the lake. Choosing any given lily pad opens up some new paths and closes down others. How do you select the right lily pads?

[From the frog’s POV, in the style of the artist Odilon Redon.]
For ambitious objectives, the right lily pads rarely resemble the objective lily pad. And the objective itself can be contested. Do we actually want flying cars? Even if the desirability of the objective is hard to contest, the form the solution should take is always open for discussion. For instance, we want to find a way of mitigating climate change, but the solution to climate change is unclear.
We often end up staring, from our lily pad, at a confusing, changing landscape without clear indications of where exactly we should search.
Trying To Find More Problems
We could try to use novelty search to solve this problem. But there’s a catch. In objective search, once you run it, and see if you make it to the objective, you’re done. Novelty search is theoretically infinite. If you have an infinite maze, novelty search will be hard pressed to find particular spots. As the search space gets larger, the chance that it finds the specific thing that you want decreases as well.
Pure novelty search also spends a lot of time in spaces that aren't that interesting. If you look again at the first animation I created, novelty search takes over 200 iterations to get around a wall.
L&S give the example of trying to evolve human intelligence from the primordial soup. Evolution is a teleonomic process, which means it appears to have a purpose (but obviously doesn't).[3]
They point out that to evolve our particular form of intelligence, at some point you had to evolve something like a flatworm, which does not remotely resemble a human. These flatworms were our ancestors. It turns out that bilateral symmetry is a useful structural condition for intelligence, but that wouldn't necessarily be obvious unless you were staring at a globe filled with symmetrical intelligent creatures.
Or take vacuum tubes, which were first used as radio-signal detectors. They rectified the very high-frequency alternating current in early radio receivers, transforming it into a direct current that could register as a signal. If you were around in 1900, trying to imagine how to build a computer, it isn't obvious that you should spend time fixing the problem of high-frequency alternating current in radio receivers.
Nonetheless, the first general-purpose programmable computer, ENIAC, depended on over 18,000 vacuum tubes. The entire thing broke down if one of the vacuum tubes broke, and this happened roughly every two days.
Vacuum tubes were a stepping stone to the computer. Bilateral symmetry was a stepping stone towards human intelligence. But how do we find more stepping stones?

[ENIAC in a U.S. army photograph. c. 1947–1955]
You can make modifications to novelty search to try and solve this problem. L&S created minimal criteria novelty search, which is a form of novelty search where results must meet a set of rules.[4]
In evolution, this would be the restriction that the organism must survive. Allowing search to run for a couple of billion years means that on our earth, creatures have explored many of the possible ways of being alive. But survival isn’t a very interesting criterion for most search algorithms that we want to run. Many things that survive are simple organisms that don’t do much beyond surviving.
L&S feel their way towards interestingness as a better criterion. They argue that we should try to explore the search space in interesting directions. Interestingness is another way of saying taste, or style. We know what things are interesting to us, but we don't necessarily know why. In a way, it is encoded in our nervous systems.
Seeing more things in a space changes the pattern of interestingness in that space for a particular actor. As Charan Ranganath puts it, "experience doesn't just change what you see, it changes what you look for." But even where greater experience doesn't offer an objective improvement in performance, experience still changes taste.
To give another example, let's think about art, which has an obvious gradient from direct, representational art, which is stuff like this:
 [The Embarkation of the Queen of Sheba, Claude Lorrain, 1648]
[The Embarkation of the Queen of Sheba, Claude Lorrain, 1648]
To indirect, more abstract works, which is stuff like this:

[Suprematist Composition, Kazimir Malevich, 1916]
Multiple studies show that the more art that people have been exposed to, as measured by, say, studying an art degree, the more people prefer abstract art. Obviously taste in art is subjective, but we're not dealing with hard rules here. We're dealing in what is interesting.[5]
You could say interestingness is a way of guiding our search, and we use it to give us an intuition about where we should start searching. Once we choose an area, we could allow novelty search to begin in that space.
The Search for Better Searching
It’s worth elaborating more on how L&S think about search. They are both artificial intelligence researchers, and discuss two heuristics which they believe were dominating AI discussions in 2015:
“A technical term for a rule of thumb that guides search is a heuristic. While no one can be sure which heuristics will work the best for getting to high-level AI, the AI community has settled upon two in particular.
The first, which we’ll call the experimentalist heuristic, follows the rule of thumb that an algorithm’s promise is given by how well it performs. In other words, an algorithm worth exploring further performs better than existing algorithms in benchmark tasks.
The second main gradient in AI research is the theoretical heuristic. This heuristic suggests that algorithms are better if they can be proven to have desirable properties.”
The experimentalist heuristic has issues that we've discussed above, namely that the best performing algorithm may not necessarily offer the best way forward. Sometimes, we have to go backwards to go forwards.
The theoretical heuristic is based on the premise that theorems usually show if algorithms will produce a good result quickly (these are the “desirable properties” they mention). If you are an AI practitioner and you have to choose between two algorithms, then it is reasonable to choose an algorithm backed by more theorems, as this suggests that it will perform at a reasonable speed.
But these theorems don't prove much about future algorithms. If you're an AI theoretician, only selecting algorithms backed by theoretical guarantees merely restricts the search space, and not in a productive way. As L&S put it:
“It means that the community becomes restricted only to those algorithms that honor the same growing set of assumptions, blinding the meta-search to every path forward that breaks the assumptions. In the end, the effect is less exploration—the objective paradox takes hold.”
It may also be the case that more powerful algorithms don't honour the same theoretical commitments.
So both options limit the search space. L&S go on to cite J.N. Hooker, who stated: “Most experimental studies of heuristic algorithms resemble track meets more than scientific endeavors".

[An algorithmic track meet, as designed by an algorithmic image generator. Specifically, ChatGPT 5.5 Thinking.]
Benchmarks have become a highly visible part of the LLM ecosystem over recent years as a way of measuring performance. Measuring performance is obviously valuable, and moving away from objectives doesn't mean discarding them altogether. But aggressively pursuing performance on benchmarks can fall into the trap of objective search. We can end up designing algorithms and models that perform well on benchmarks, instead of algorithms that find new and interesting things.
How To Be Interesting
One way to be interesting is to be random. People often make fortunate discoveries while doing random things, which we term serendipity. Serendipity was coined by the writer Horace Walpole, who, in a letter to a friend, described a Persian fairytale called The Three Princes of Serendip. In the tale, the three heroes kept making fortunate discoveries, by a combination of accident and sagacity, of things that they had never intended to find.
From his Wikipedia: "According to legend, one day while building magnetrons, Percy Spencer was standing in front of an active radar set when he noticed the candy bar he had in his pocket melted."
Percy Spencer then went on to use that information to invent the microwave.
From the blogger Malmesbury:
"Aspartame was discovered accidentally by a chemist researching a completely unrelated topic. At some point, he licked his finger to grab a piece of paper and noticed a strong sweet taste.
Saccharin was discovered by a researcher who ate bread without washing his hands and noticed the bread was sweet.
Acesulfame K was also discovered serendipitously by a chemist licking his fingers, although the legends don’t specify the exact circumstances behind the finger-licking."
People who build recommender algorithms are aware that serendipity is a critical part of a search algorithm, although it is highly difficult to explicitly code it into an algorithmic recommender.
One way to get serendipity is through a little bit of randomness. There is a study that argues that as scientific articles stop being published in printed journals, scientists get less creative because there is less random overspill from other articles they wouldn’t have normally read. When you're online, you can filter more effectively, which can offer visible benefits and hidden disadvantages.
Randomness isn't a complete solution. Randomness is not a quality filter, and randomly searching through very large search spaces takes a long time. Most of us aren't Percy Spencer, and would probably be pissed off by a chocolate bar melting in our pocket, rather than spotting the connection.
As the next line of his Wikipedia notes pointedly: "Spencer was not the first to notice this phenomenon, but he was the first to investigate it." In the same vein, we’ve all spent a lot of time licking things. Few of us would know which licks were significant scientifically and fewer would know how to synthesise a new chemical compound after that lick.
The Interesting Properties of Science
The space of interestingness is intensely relational. What is interesting to you is not necessarily what is interesting to me, and those differences in belief greatly influence the research we do.
One of the implications that follows from this is that, at least at the cutting edge, there should be more than one theory for interpreting what is going on. Competing ideas which offer a form of scientific pluralism offer a compelling framework for understanding the world. A wider variety of options allows for different forms of good.
One way that this pluralism is captured in current AI is by a field of algorithms that L&S pioneered called Quality Diversity (QD) algorithms, which attempt to try and generate multiple good solutions to the same problem. This is similar to the way evolution developed many millions to billions of possible ways of being alive, such as the bearded vulture, the only vertebrate whose diet is mostly bone.

[A bearded vulture eating a bone. Their common name is ossifrage, from the Latin for “bone-breaking”.]
A frequent collaborator of L&S, Jeff Clune and his team recently tried to formalise the concept of interestingness using a method they call OMNI. This takes a candidate idea and scores it with a function of interestingness. The insight here is that you can use a foundation model (or an LLM) as a proxy of interestingness, because a foundation model contains the internet, and the internet was written by humans, who know what is interesting. Once you have a function of interestingness, you can score candidate tasks or environments and then run checks for nearby candidates with higher scores.
[Measuring interestingness. An example from Clune et al. (2025)'s more recent paper, which lets OMNI use code environments.]
The algorithm you are using to search in any particular field determines the set of possible outcomes. We can search for more things, and have to spend more time filtering on the other side, or we can be more restrictive and potentially miss out on valuable stepping stones. Whatever the field, whatever the algorithm, we are always navigating this trade-off.[6]
However, using better search algorithms might help us to spend less time filtering without missing out on as many stepping stones. And L&S argue that one of the best ways to improve search is to avoid consensus, which is usually created by a stringent form of objective search.
As they put it, "seeking consensus prevents traveling down interesting stepping stones because people don’t agree on what the most interesting stepping stones are."
Using what is interesting is a useful way to restrict the search space. Many of our greatest theories came from a combination of a scientist's intuition for the interesting and their willingness to explore that search space even if initially they were not successful. The discovery of penicillin by Alexander Fleming was serendipitous, but Fleming himself wasn’t able to purify it into a clinically usable drug. Much of that work was carried out by a team led by Howard Florey.
The truth is that we often don't know what we're looking for, so throwing away the objectives of a research programme can actually be helpful in some ways. It's obviously difficult to communicate this to funders: "Sorry, you want a bunch of money to get bats loaded?" But L&S argue that less stringent restrictions may allow us to create more serendipity and to find more stepping stones.
Interesting work usually meets a quality filter, but beyond that filter, ranking them doesn't add much. Is The Shawshank Redemption, which is perennially ranked first on IMDb, really more worthwhile in any meaningful way than The Godfather, which is ranked second? The answer is obviously not. Both films pass the quality filter, but one is a biting excoriation of the prison system and the other is about not asking guys to do things on the day their daughter is getting married.
As Paul Feyerabend, a 20th century philosopher of science, put it:
“Knowledge so conceived is not a process that converges toward an ideal view; it is an ever increasing ocean of alternatives, each of them forcing the others into greater articulation, all of them contributing, via this process of competition, to the development of our mental faculties.”
The Great Theory Showdown
But films aren't science, I hear you cry. And this idea sounds very unintuitive. Surely we should always rely on our strongest theory? Well, for one thing, it can be hard to determine what our strongest theory is. But the other problem is that the strongest theory now isn't necessarily the one that allows us to make the most progress in the future.
Karl Popper proposed that science should rely on the falsification approach, which holds that for a theory to be scientific, it must be testable and disprovable by observation or experiment. Although this idea is commonly accepted as one of the backbones of modern science, it is less valid than it might intuitively seem.
It was contested by the Hungarian philosopher Imre Lakatos, who argued that there are famous cases where theories that would have been falsified under a Popperian programme were later proved true.

[Imre Lakatos, source.]
One of Lakatos’ favourite examples is the story of the Copernican revolution. Before the 16th century, the dominant view of space relied on the Ptolemaic geocentric model, in which the Earth stood still at the centre of the cosmos while everything else moved around it. This has now been replaced by the Copernican theory of heliocentrism which predicts that the Earth orbits around the sun.
If Copernicus was right, and the Earth moves around the sun, then our view of the stars should change during the year. When the Earth is on one side of its orbit, we are looking at the stars from one position. Six months later, when the Earth is on the other side of its orbit, we are looking at those same stars from a different position. So the closest stars should appear to shift very slightly against the background of more distant stars, which should shift much less. This effect is called stellar parallax.
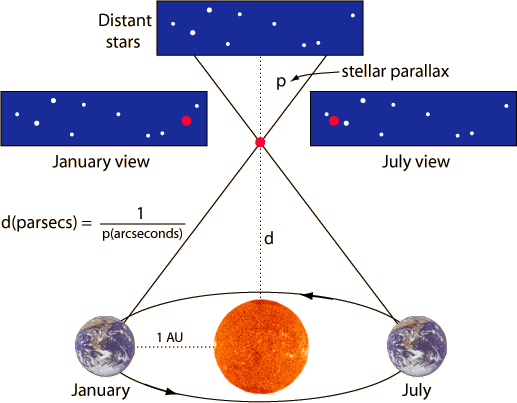
[A visual to help clarify stellar parallax. Source.]
Until 1838, stellar parallax was not observed. This is because the shift in location is incredibly slight, and you need very powerful telescopes to detect it. Nonetheless, by 1838, the heliocentric view was the dominant model, because a theory is generally assessed against all of its parts. For instance, accepting Copernican theory meant that retrograde motion no longer had to be treated as a strange independent loop made by each planet.
The full story of the Copernican revolution has been better told elsewhere, but the point is that if we adopt an approach to science depending entirely on falsification, we might end up throwing out work before it has been able to prove itself, much in the same way that we might throw out interesting work if rely only on its current performance.
Lakatos thus suggested that research programmes should have a set of central hypotheses, which formed the core of any programme, coupled with auxiliary hypotheses, which are allowed to change in the face of new evidence.
But if we can't just rely on falsification, how do we solve the demarcation problem between science and pseudoscience? Well, for Lakatos, real science allows you to make predictions that have not previously been observed. As he wrote:
"All the research programmes I admire have one characteristic in common. They all predict novel facts, facts which had been either undreamt of, or have indeed been contradicted by previous or rival programmes."
Newtonian mechanics allowed Halley to predict the arrival of his namesake comet some 70 years later, long after both he and Newton were dead.
I would extend Lakatos' argument here in the spirit of L&S to say that we want our research programmes to make new predictions in spaces that are interesting. Interesting predictions often give you new capabilities, even if they weren't the ones you were looking for.
A novel prediction about something boring is a little pointless. If I glue a banana and an apple together and then make a bunch of predictions about when they will eventually fall apart, that doesn't let me achieve many new things and wastes a lot of glue. If I make a bunch of predictions about the ways robots could achieve locomotion, as Lipson et al. (2013) did, then that creates a lot of possibilities for new walking robots.

[Video accompaniment to the paper: Unshackling Evolution: Evolving Soft Robots with Multiple Materials and a Powerful Generative Encoding. Cheney, MacCurdy, Clune, & Lipson. Watch their full video of possible forms of locomotion here.]
Research programmes focusing on what is interesting might allow people time and space to explore ideas, even if they don't meet stringent criteria now. As Peter Higgs put it, "It's difficult to imagine how I would ever have enough peace and quiet in the present sort of climate to do what I did in 1964. I wouldn't be productive enough for today's academic system."[7]
Defining an interesting scientific programme means allowing scientists to get things wrong. It also involves allowing them to present ideas that are not immediately optimal or better than what we currently have. Many of the criteria we currently have around funding research programmes and science more generally are supposed to act as a filter so that people can't introduce junk science into the scientific community. L&S respond to this argument by pointing out that experts in most fields know what junk is, and the insinuation that they need a set of rules to see that junk is a little insulting.
The idea isn't to remove minimal criteria altogether, but to allow scientists to exist in a Goldilocks zone, where they are allowed room to explore and find stepping stones, without being forced to map their research onto a set of unhelpful objectives.
I’ve focused on science in this review, but L&S’s argument applies everywhere, and you should be thinking about the search algorithm that is being used in your specialism. We are all manipulated by external search algorithms, whether we like it or not. To succeed anywhere, most of us have to optimise ourselves according to a search algorithm that dictates success in that field.
To become a doctor, lawyer or a kangaroo scientist, you typically have to show that you are good at passing medical assessments, sitting legal exams or cleaning pouches. This means playing the game and proving you are good at playing it. Every field is engaged in some form of search to find people, and those criteria end up deciding who we send to Australia to study kangaroos. Being aware of this structure is the first step towards potentially changing it.
Giving Up The Goal
Why Greatness Cannot Be Planned is a wonderfully broad book. While I've discussed search spaces and algorithms extensively, they discuss the impact of objective search in all parts of life.
Dampening the quest for the objective can be helpful for a lot of people. We all want to achieve things in life, and it can be disappointing when we don't achieve them. But L&S argue that using ambitious objectives as a guiding star can hinder us as much as it helps.
This isn't to say that you should stop setting goals for yourself, but if you want to use goals, set modest ones. Ambitious goals are things you arrive at sideways. Adopting the worldview that L&S inhabit means accepting that you can't always get what you want. But if you try sometimes, you just might find… sorry, I'll stop.
People make great discoveries in places where they least expect them. To take advantage of serendipity you have to be both constantly looking for interesting things and also possess the expertise to see them.
The Wright Brothers were experienced bicycle manufacturers who saw that the conditions were right for flight. Percy Spencer discovered the microwave because of serendipity but also because he was one of the world's leading experts in radar tube design.
In the spirit of Imre Lakatos’ example, I'm going to analogise this to the Ptolemaic system of planetary motion.
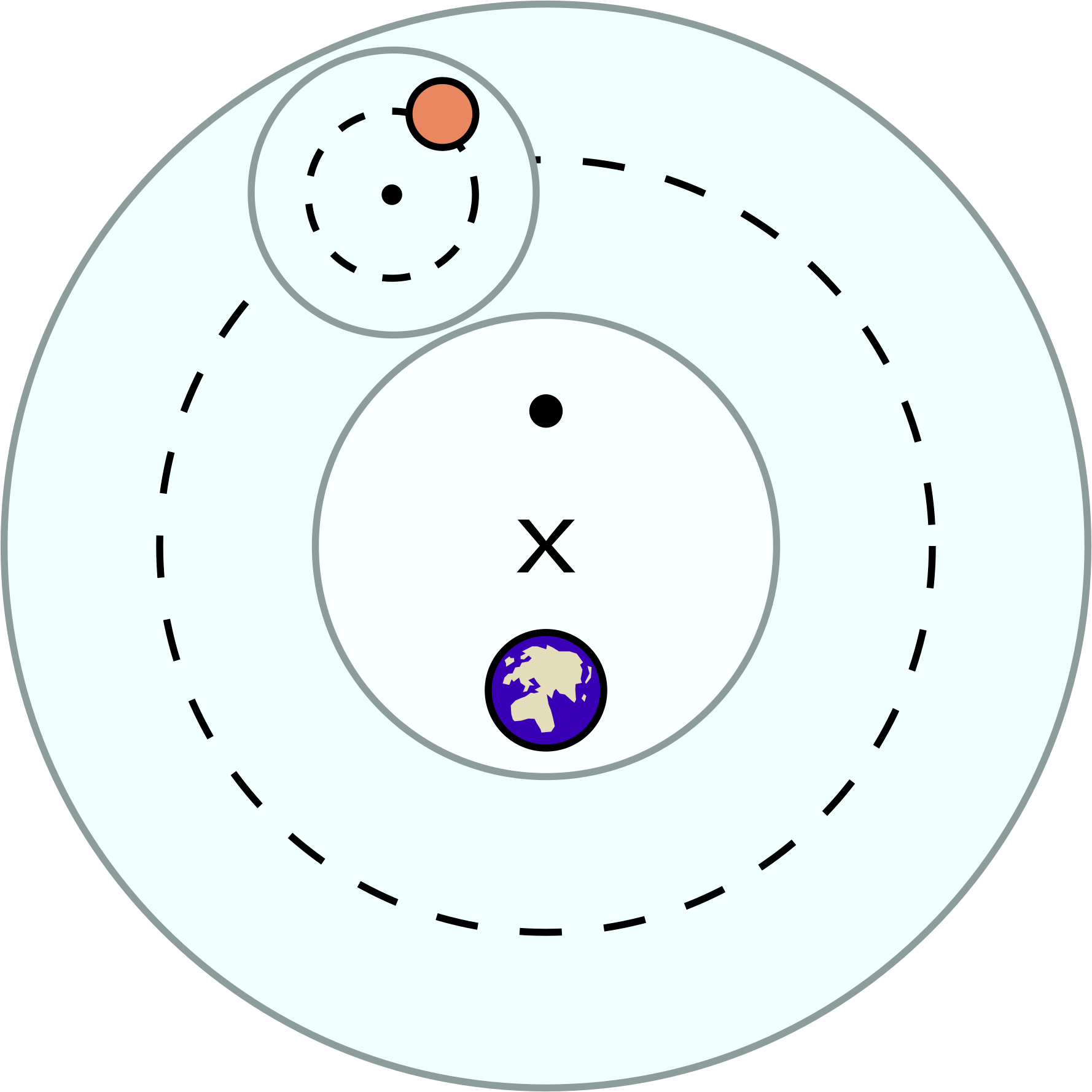
[The basic elements of Ptolemaic astronomy, showing a planet on an epicycle (smaller dashed circle), a deferent (larger dashed circle). Source.]
Planets move on a deferent (the larger dashed circle), and in this metaphor, that represents the spirit of constant learning and development in a field. You want to keep developing your expertise so that you're ready to spot new ideas when they arrive.
But planets also move on an epicycle (the smaller dashed circle). In this analogy, the epicycle represents wiggling around in the hunt for serendipity.
Subscribe to a weird journal. Go to a strange book club. You don't even have to interact with other people. I recently made a small app where I give it articles I want to read. A month later, and it’s emailing me every day with articles that I had completely forgotten I was interested in.
Serendipity helps to shatter a mould that we didn’t imagine ourselves to be trapped in.
As Lois Bujold puts it, “It's a bizarre but wonderful feeling, to arrive dead centre of a target you didn't even know you were aiming for.”
Your message is stored now and emailed to the author after the contest ends. The author can reply to you, but their identity stays hidden unless they choose to respond.
Footnotes
- ↩
A control purpose here just refers to a form of objective search. In a classic and perhaps apocryphal example, the British wanted to reduce the number of cobras in India, and began paying for dead cobras. So the Indians started breeding cobras to kill and give to the British, in order to get the reward.
- ↩
It's not quite as straightforward as it seems to just explore new areas, sometimes we have to go through old areas to explore new ones, but it is possible to design algorithms that solve this problem.
- ↩
All creatures need to “survive and reproduce”, but L&S make the case that this should be seen as a constraint, rather than an objective.
- ↩
There are other possible variants of these algorithms. If you’re interested, I’d start by looking at MAP-Elites and POET.
- ↩
And such ideas also apply outside the world of art. Herbert Simon found that chess grandmasters see the board very differently to amateur players, quickly chunking the board into discrete patterns. This applies across all areas of expertise.
- ↩
According to David Wolpert and William Macready's No Free Lunch Theorem, there is no 'best' algorithm for searching. The 'best' algorithm depends on the constraints of your particular problem. If you have reliable assumptions about the structure of the objective landscape then you can choose or design an algorithm that exploits those assumptions. But if the search space is hard to determine, or it is changing, these designs are less likely to work.
- ↩
In 1964, Higgs theorised the existence of an invisible, universe-wide field that gives other fundamental particles their mass, and predicted the existence of the particle associated with this field, which became known as the Higgs boson.